Vibe Doctor:讓 AI 訪談你,自己長出一個論文初評工具
不用先背 Prompt Engineering。讓 Claude AI 先訪談你,再把醫師的評讀標準整理成一個可重複使用的論文初評工具。

先交代一下系列脈絡。前面三篇走的是「教」這條線,把一份講稿丟進 NotebookLM 換成簡報與播客、用 ChatGPT+Codex 把水腫回顧做成 PPT、再用 Claude Design 做同一份簡報的對照。那是把已經有的內容換裝。
從這篇起,我們轉進「研」這條線。第一站要處理的,是醫師最重複、最耗神經、卻又最需要專業判斷的一件事:讀一篇論文,快速判斷它可不可信、能不能用在病人身上。 我們不直接教你「怎麼讀」,而是教你怎麼做一個助手,每次都用同一套標準替你把第一輪做完。
AI 年代,很多人大概都聽過 Prompt Engineering 這個詞。再往後,又開始有人談 Context Engineering、Harness Engineering,甚至把工作流裡不斷回饋、修正、驗證的部分稱為 Loop Engineering。
名詞越來越多,問題也越來越實際:繁忙醫師在教學、研究、門診與病房工作之外,到底要怎麼掌握這些東西?如果只是想讓 AI 幫忙做一篇醫學論文初評,真的需要先變成提示詞工程師嗎?
傳統 Prompt Engineering 會說:你不能只是說「請幫我評論這篇論文」。你得交代研究類型、PICO、偏差風險、統計方法、效應量、臨床適用性、利益衝突、輸出格式,還要提醒 AI 哪些地方不能假裝查過。
可是,誰會在日常聊天時一次記得這麼多面向?我們通常是先想到幾件事,後面才補充、修正、追問。這篇要示範的,剛好是反過來:你一句提示詞語法都不用寫,照樣能做出一個可重複使用、而且相當講究的論文初評工具。 你只需要會一件每天都在做的事:回答問題。

一、「你得先變成提示詞工程師」是個誤會
很多人對 AI 卻步,是因為網路上把「寫好提示詞」講得像一門要修煉的功夫:要角色設定、要思維鏈、要範例、要輸出格式……看完只覺得,這是工程師的事,不是臨床醫師的事。
但其實你要的東西很單純:一個每次拿到新論文都能套用、輸出穩定、不會漏掉重點的初評提示詞。 與其自己從零拼湊這段文字,不如反過來——讓懂這件事的 AI 來訪談你,把你心裡那套「好論文長什麼樣」問出來,再幫你寫成提示詞。
你出的是專業判斷;AI 出的是把它整理成工具的力氣。這就是這篇的方法。

二、方法:讓 AI 先問你「該涵蓋哪些面向」
整個手法只有三步,核心是翻轉:不是你去想提示詞,而是 AI 先問你。
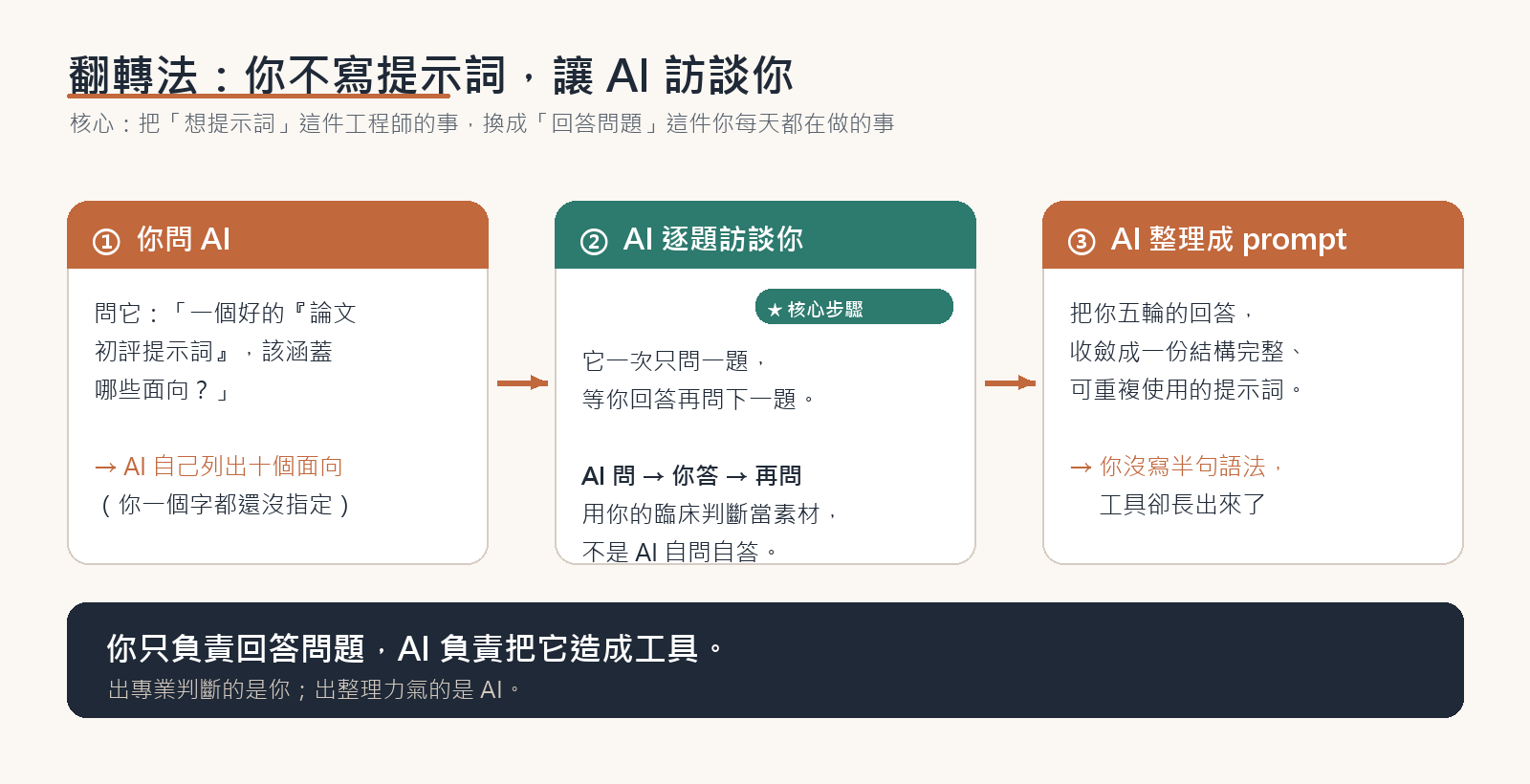
第一步,先別急著要它寫提示詞,而是問它:「一個好用的『醫學論文初評提示詞』,通常應該涵蓋哪些面向?」
這篇文章我們先把這個問題輸入到 Claude AI 裡面實測,看看它會怎麼回答。結果如截圖所示,它列出的不是幾句空泛建議,而是一整組論文初評該涵蓋的面向:
- 論文基本辨識與分類:這是什麼論文?
- 研究問題與假設 PICO:它想回答什麼?
- 研究設計與方法品質:做法可不可信?
- 偏差風險評估:結果可能被什麼扭曲?
- 統計方法與分析:數字算得對不對?
- 結果與效應量解讀:結果多大、多確定?
- 結論合理性與過度詮釋:作者有沒有講過頭?
- 外在效度與臨床適用性:對我的病人有沒有用?
- 利益衝突與資金來源:有沒有立場污染?
- 整體評等與後續行動:我該怎麼用這篇?

值得停一下:這份清單是 AI 自己提出的,我們一個字都還沒指定。換句話說,「一個好的論文初評該檢查什麼」,它本來就知道——你要做的只是告訴它,在這些面向裡,你個人最在意什麼、要做到多細。
三、實跑三步驟:讓它一題一題訪談你
⚠️ 練習素材是合成論文。 接下來的實測使用一篇虛構的腎臟科合成論文,不是真實研究、沒有真實病人,也不可作為臨床證據或醫療決策依據。下載連結會放在 §六,方便你對照實跑結果。
接著只要請它:「就用你列的這十個面向,一題一題訪談我,一次只問一個,問完等我回答再問下一個,不要自己幫我預設答案。」
同樣的,我們把這個要求輸入到 Claude AI 裡面。結果它真的開始當訪談者了,這一步其實很令人驚訝:它不是直接替醫師下結論,而是先把醫師心裡的標準問出來。
第一題,它問研究類型:「你拿到的論文大多集中在某幾種類型,還是什麼都可能遇到?要不要內建『自動判斷類型、再切換對應評讀框架』的邏輯?」

你只要照實回答——我大多讀 RCT 和統合分析,但也常遇到世代研究、registry,所以希望它先自動判斷類型、預設以介入型 RCT 為主。它收下,接著問 PICO、問偏差評估要多正式、問統計與效應量、問適用性與利益衝突……
過程中它還會幫你做兩件你自己未必會做的事:
- 主動點出陷阱。問 PICO 時,它提醒我要不要固定檢查「替代指標(surrogate)」和「複合終點(composite)」——這正是論文摘要最容易誤導人的兩個地方。
- 守住誠實邊界。當我說想比對試驗註冊資料,它老實說「AI 沒辦法單從論文內文確認這件事」,建議改成由提示詞提醒你去查、並標成「需人工查證」,而不是讓它自己假裝查過。
你可能會發現一個落差:剛剛不是列了十個面向,怎麼五輪就問完?因為我請它「盡量五到六輪問完」,它就把關係相近的面向併在一起問:
| 輪次 | AI 併著問的面向 |
|---|---|
| 第 1 輪 | 面向 1:研究類型 |
| 第 2 輪 | 面向 2:PICO/終點 |
| 第 3 輪 | 面向 3+4:設計品質+偏差風險 |
| 第 4 輪 | 面向 5+6+7:統計+效應量+結論詮釋 |
| 第 5 輪 | 面向 8+9+10:適用性+利益衝突+整體評等 |
所以「十個面向」和「五輪問完」並不矛盾——一個講的是檢查的面向數,一個講的是問答的回合數。五輪走完,它把我的回答整理成一份完整、結構清楚的提示詞:

接著我們請 Claude AI 依訪談內容產出成品 prompt。從頭到尾,我沒有寫任何一句提示詞語法,只是回答了幾個臨床上本來就有定見的問題。
📄 想看完整的五輪問答——每一題、每一輪回答,到最後產出的提示詞全文?下載完整訪談對話逐字稿 PDF(6 頁,合成示範用,內含揭露聲明)。
四、收斂點:它問出來的,就是「六要素」
如果你把它訪談的脈絡攤開,會發現它其實在替你補齊一個好提示詞的六個要素:

Role(角色):要它扮演嚴謹的臨床流行病學與實證醫學評讀助手。
Context(情境):你常讀哪類論文、最在意哪些判斷、預設要處理哪種研究設計。
Task(任務):要它做初評,不是寫摘要,也不是替醫師做最後定論。
Constraints(限制):不得臆測、不捏造、缺數據不硬湊、主要/次要/探索性終點不能混談。
Output format(輸出格式):固定成 0–9 節架構,讓每次輸出都能掃讀、比對、補查。
Verification(查核):凡無法從內文確認,一律標【需人工查證】,不要假裝查過外部資料庫。
更有意思的是,這套「自己長出來」的結構,跟實證醫學界既有的 critical appraisal 框架(PICO、outcome hierarchy、偏差工具、適用性、保守結論)幾乎是同一套。你不必去背它——只要讓 AI 訪談你,它自然會把你帶到那裡。
五、把提示詞「停進」Claude Project,變成常駐工具
訪談生出的提示詞,如果每次都要手動複製貼上,它還只是一段文句。更麻煩的是,幾週後你可能連它存在電腦哪個檔案裡都忘了。
所以第二步,是把這段提示詞變成一個可以重複利用的工具。我們這次用 Claude Project 示範:開一個新 Project,把訪談產出的提示詞、加上一段醫療安全與責任邊界,一起貼進 Project instructions。
這樣一來,等於讓這位副官正式編進船員:每次打開這個 Project,那套初評規則就已經在位。以後每拿到一篇新論文,把 PDF 附上、打一行「請依本專案的指示,對這篇論文做初步評讀」,常駐提示詞就會自動套用——不必每次重新喊它上來。
Claude Project 不是唯一能做這件事的地方。ChatGPT、Gemini 也有類似的常駐脈絡或自訂工具做法,我們後面會再介紹。這篇先把一件事做穩:讓論文初評 prompt 不再是一段容易遺失的文字,而是一個打開就能用的工作空間。
六、實測:用它跑一篇論文
為了說明這篇文章的概念,我們模擬書寫了一篇虛構的醫學論文。請注意,這篇醫學論文是教學用的合成素材,目的是讓讀者有一份可以公開體驗的測試材料;它不是真實研究,不可引用,也不可作為臨床證據。
你可以先下載這兩個版本對照:英文整合版是本次實跑使用的主檔,中文整合版方便讀者快速理解內容。
素材備妥,我們就讓這位副官跑第一輪。把英文版 PDF 附到 Claude AI 的「醫師論文初評助手」Project,只打一句話觸發:「請依本專案的指示,對我附上的這篇論文做初步評讀。」它依專案指示,跑出一份照固定 0–9 架構走的初評,每一節都替你把一類問題問完:
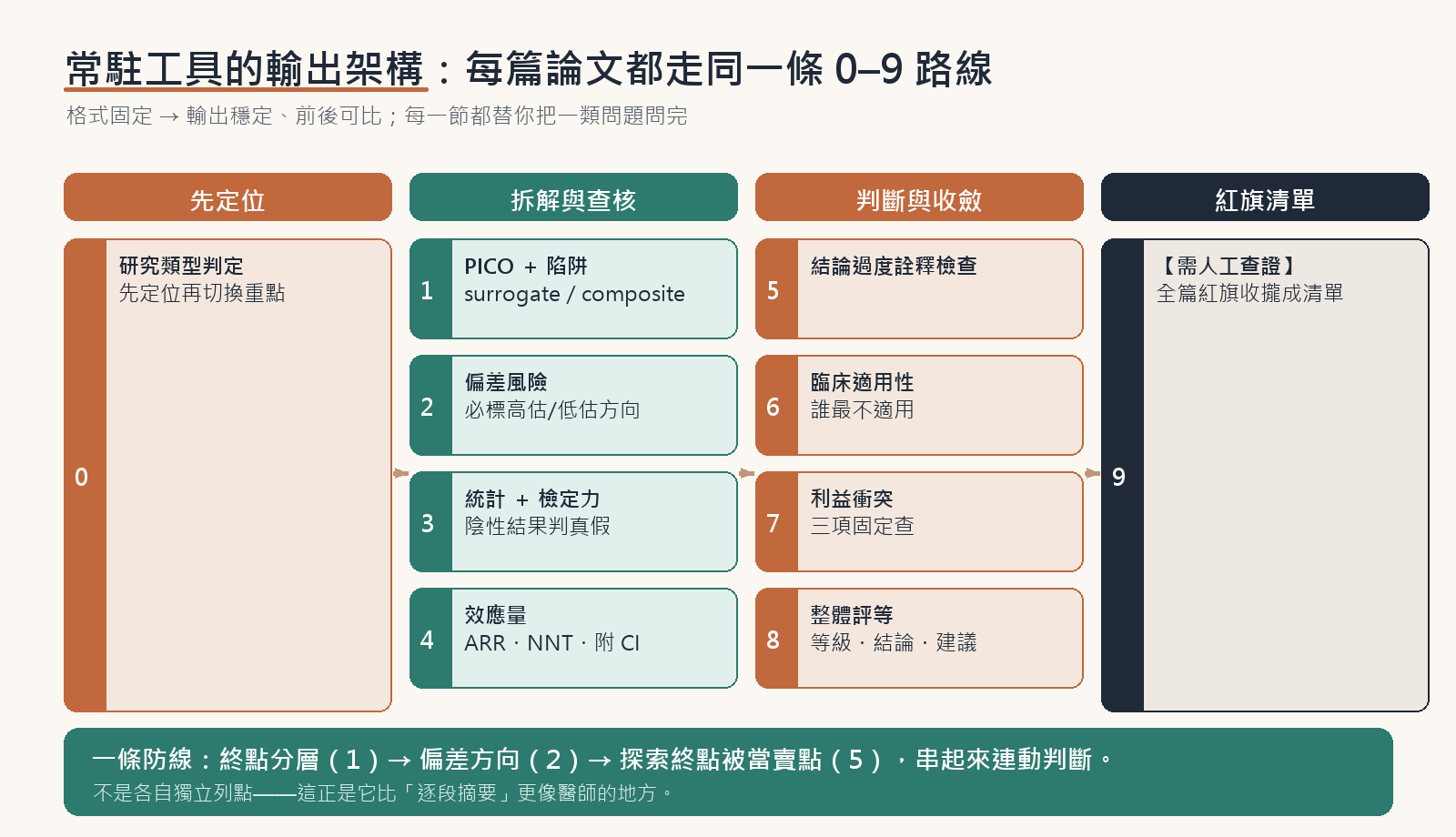
實際的輸出,開頭先聲明這是合成教學稿、不可當臨床證據,接著判定研究類型、拆 PICO、分層終點:
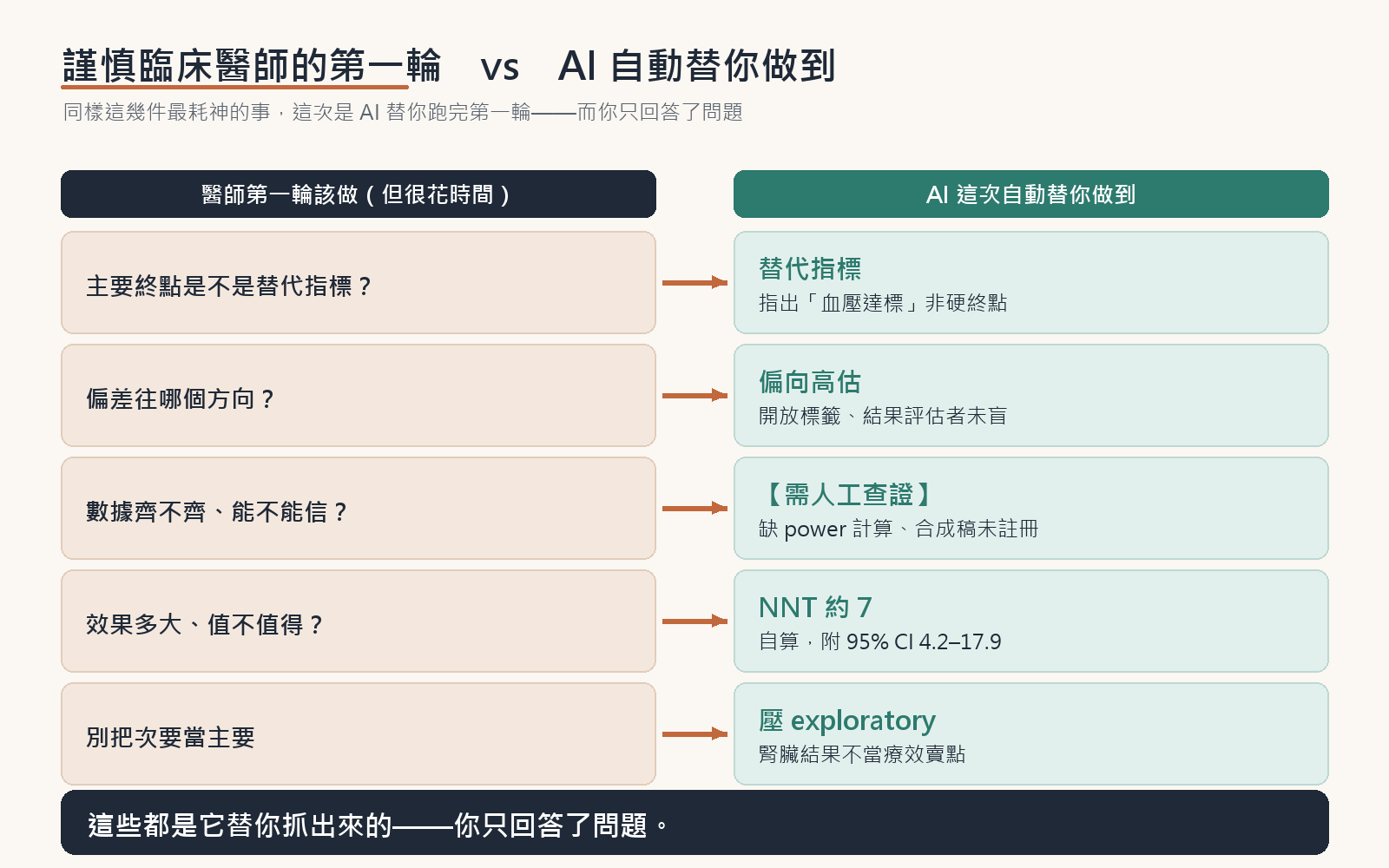
再往下看,才是讓人哇哦一聲的地方。Claude AI 沒有只給一段摘要,而是做了一個謹慎的臨床醫師會做、但很花時間的初步檢查:
- 它一眼指出主要終點「血壓達標」是個替代指標,不是硬終點——血壓達標率上升,不等於心、腎或存活結果改善。
- 它標出偏差的方向:開放標籤、結果評估者未盲,會讓效果偏向高估。
- 它把缺的東西老實標出來:全文沒有 power 計算說明 → 標【需人工查證】;合成稿未註冊 → 主要終點有無被改「無法核對」。
- 它自己算出 NNT ≈ 7(校正風險差 +14.8 個百分點,95% CI 換算後約 4.2–17.9 人),SBP 多降約 5.6 mmHg,並把代價一起講:症狀性低血壓較多(8.6% vs 4.8%)、監測負擔較高。
- 它把腎臟結果壓在 exploratory,拒絕把它當療效賣點。
最後給出整體評等——血壓這個替代終點的證據等級「中等」、腎臟/硬終點「低/不適用」;行動建議「僅供參考」(因為是合成稿);並收攏一張「最需要人工查證」的清單。

把驚嘆說清楚:我沒寫半句提示詞語法,它卻把這篇論文最容易被高估的地方一條條挑了出來,還誠實地告訴我哪些它不能替我確認。這不是「AI 好神」的浮誇,而是它真的替你省下了第一輪最耗神的工,把你的注意力留給最後該由你做的判斷。
七、責任邊界:AI 整理,醫師定案
這套工具的價值,建立在一條清楚的界線上:它做的是「初評」,不是「定論」。
- 它輸出的那張【需人工查證】清單,不是麻煩,而是紅旗——在你自己核對之前,這些地方不能輕信。
- 凡涉及診斷、檢查判讀、用藥、治療的具體內容,最終仍須由醫師依專業與在地臨床指引確認。
- 合成稿是教學素材,不可作為臨床證據;真實論文也一樣,AI 的整理必經人工核對。
- 還有一條硬規則:不要把可識別病人資料、病歷或報告貼進未經治理的 AI 工具。
副官把資料攤開、把框架擬好、把雜務加速;定案的那一筆,永遠是醫師自己落。
八、完整提示詞(可直接照抄)
下面是訪談產出、我們停進 Project instructions 的那份提示詞全文。你可以整段複製,換成你自己的訪談答案後使用。
提醒:放進你自己的工具前,把醫療安全與責任邊界(不提供臨床建議、不對特定病人下處置、合成或敏感內容的揭露)一起寫進 instructions,讓每一次輸出都守同一條線。
結尾:你只是回答問題,就得到了一個工具
回頭看這趟航程:你沒有當提示詞工程師,只是回答了幾個臨床上本來就有定見的問題;換來的,是一個會用同一套嚴謹標準、每次都替你把論文第一輪做完的常駐副官。
這位副官已經上了船——只是每趟出航,你還得親手解纜:開對話、貼上論文、存檔,一步都少不了。
下一篇,我們替它裝上引擎。用 Google Apps Script 打造一顆按鈕,按一下就啟航:自動跑完初評、自動把紀錄記進航海日誌。讓每天那些重複的手活,收進一次俐落的點擊。
備好船,下一段航程更輕快——我們下一篇見。⚓