Vibe Doctor:論文初評助手,從「聊天機器人」升級到「會自己動手的 Agent」
你出需求、它出手——這趟看 Agent 自己建工具、自己撞 bug 自己修的全程實錄,帶出 harness engineering 的概念,與「該換 Agent 的時機」。


上一篇,我們用聊天機器人(Gemini)把一份論文初評做成了一個會跑的網頁。它真的能寫程式、也能幫你除錯——但你大概還記得那個結論:它只會「出嘴」。F12 是你開的、錯誤訊息是你複製貼回去的、程式是你一段段貼上去的、部署是你按的、連發現是瀏覽器快取,也是你自己換無痕視窗試出來的。聊天機器人很能幹,可是它看不到、也碰不到你的東西。每一次,都是你在跑腿。
這一篇,我們把「動手的那個人」換掉。
不是換一個更聰明的聊天機器人,而是換一種工作流:Agent。具體說,是用 Claude Code 調用 Claude in Chrome——它不只出嘴,還出手:自己打開瀏覽器、自己建專案、自己貼程式、自己設定、自己部署、撞到 bug 自己看 console、自己改、自己重新部署、自己驗證。你只負責一件事——把要什麼講清楚。
先說在前頭:我還是那個不會寫程式的醫師。這一篇從頭到尾,我幾乎沒有自己動手貼過程式、也沒有自己除過錯——我做的,是在旁邊看著它做、需要我簽名授權時按一下。如果你也好奇「AI 自己寫程式」到底長什麼樣子,這篇就是一次完整、誠實的實錄,包含它真的撞到的 bug、和我們真的踩到的限制。
⚠️ 本篇一律用合成(虛構)論文示範。 文中那個網頁工具是教學原型,不可輸入病人可識別資料、也不可作為臨床決策依據。AI 整理、醫師定案。

一、這次的目標:從零、做一個「更大」的工具
上一篇那個工具很小——四個功能,一份需求,聊天機器人一次就能產完。小專案,聊天機器人剛剛好。
但真實世界的工具會長大。所以這次我們刻意把題目放大:請 Agent 從零做一個「論文初評工作站」,而且不只做出來,還要一邊長大——先做出基礎版(跟上一篇等價:貼論文、一鍵初評、存進試算表、回看歷史),再往上加功能:多種評讀輸出(完整初評報告、Evidence Card、臨床決策摘要)、把卡片另存成結構化的工作表、還要把它做得夠穩(模型忙線時會自動重試、甚至換備援模型)。
程式越長、改越多次——這正是要凸顯的地方:到了這個規模,「換它出手」的價值才真正浮出來。

二、什麼叫「Agent 出手」?
上一篇的分工是:它出嘴、你出手。 聊天機器人把程式碼吐給你,剩下的——貼到哪、怎麼存檔、怎麼部署、怎麼除錯——全是你的事。
這一篇的分工是:你出需求、它出手。 Agent(Claude Code 調 Claude in Chrome)會直接在你的瀏覽器裡:
- 打開 Google 雲端硬碟、建一個資料夾、開一個 Apps Script 專案;
- 把它自己寫的後端與前端程式貼進編輯器;
- 到專案設定裡放好 API 金鑰、部署成網頁;
- 部署後親自打開網址測試、貼上論文跑一次;
- 撞到錯誤時,自己讀錯誤、自己改程式、自己重新部署、自己再測一次。
在開始之前,先認得這兩種工具長什麼樣。你大概用過聊天機器人——Gemini、ChatGPT、Claude AI 那種一問一答的;而這一篇的主角,是它們的進階版:Agent。市面上幾個代表是 Antigravity、ChatGPT 的 Codex,還有我們這篇用的 Claude Code。
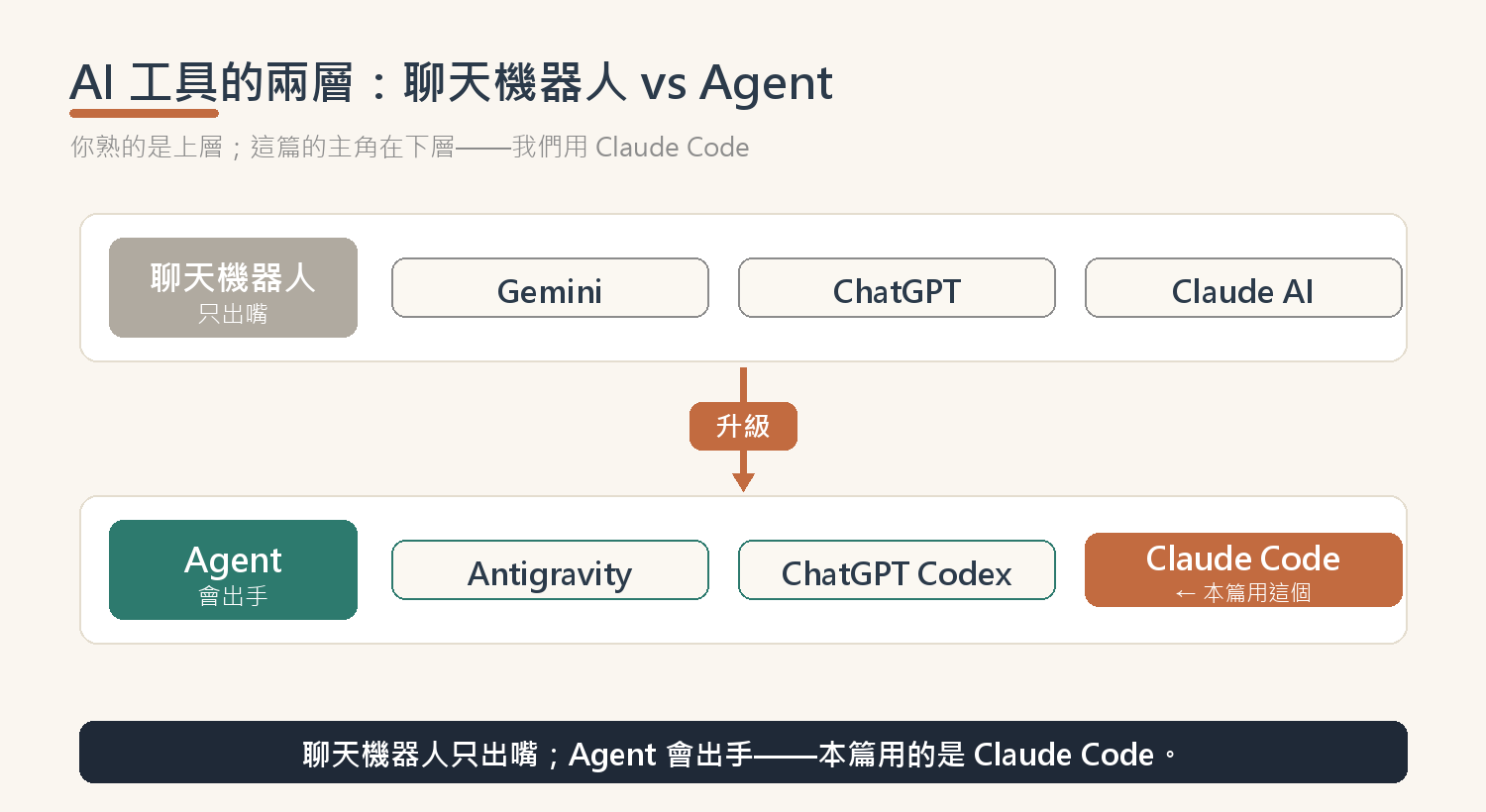
說實話,Claude Code 原本是給工程師的終端機工具,非開發者看到那個黑底視窗大概會卻步。但現在門檻低多了:你可以在 Claude 桌面版裡直接切到「Code」分頁就開始用,工程師則另有 IDE 外掛可裝;而且只要**訂閱 Claude(Pro 以上方案)**就有資格用。換句話說——這東西,不寫程式的你也碰得到。
你從「操作員」變成「出題者」。下面就是它一步步做的實況。

三、看著它徒手把工具建起來(基礎版)
想自己跟著做?從這裡起手。 這一段不只是看,你可以照著做做看。
先講一個前置:這一篇之所以能看到 Agent「直接」在瀏覽器裡動手,是因為它會去調用一個叫 Claude in Chrome 的瀏覽器外掛。所以跟著做之前,先備好兩樣——① 裝好 Claude in Chrome 外掛;② 開著 Chrome、保持登入(含你等一下要用的 Google 帳號)。這樣 Agent 才有一個「能動手的瀏覽器」可用。(至於 Claude Code 本身怎麼取得,上一節說過了:Claude 桌面版的「Code」分頁、IDE,或訂閱 Claude Pro 以上方案。)
備好之後,正式起手——四步:
- 下載這份需求規格:📄 軟體需求規格.md(點此下載)。這就是我交給 Agent 的同一份需求文件。
- 把它放進一個(空的)資料夾,當成你這個小專案的家。
- 用 Claude 桌面版裡的「Claude Code」打開這個資料夾(把整個資料夾當成一個「專案」開)。
- 跟它說(可以直接照抄這句):
「看一下資料夾裡的需求文件,告訴我你對它的理解。先不要做任何動作,等我確定你都理解了再開始。」
這句話,是整個協作姿態的縮影:先讓 Agent 把需求讀懂、用它自己的話講回給你聽,別急著讓它動手;你確認它真的理解了,再放它出手。你出題、它出手——但方向盤一直在你手上。
這就是它跑起來的樣子——左邊是 Claude(桌面版)的「Code」工作區,中間就是它讀完需求、把理解講回給我聽:
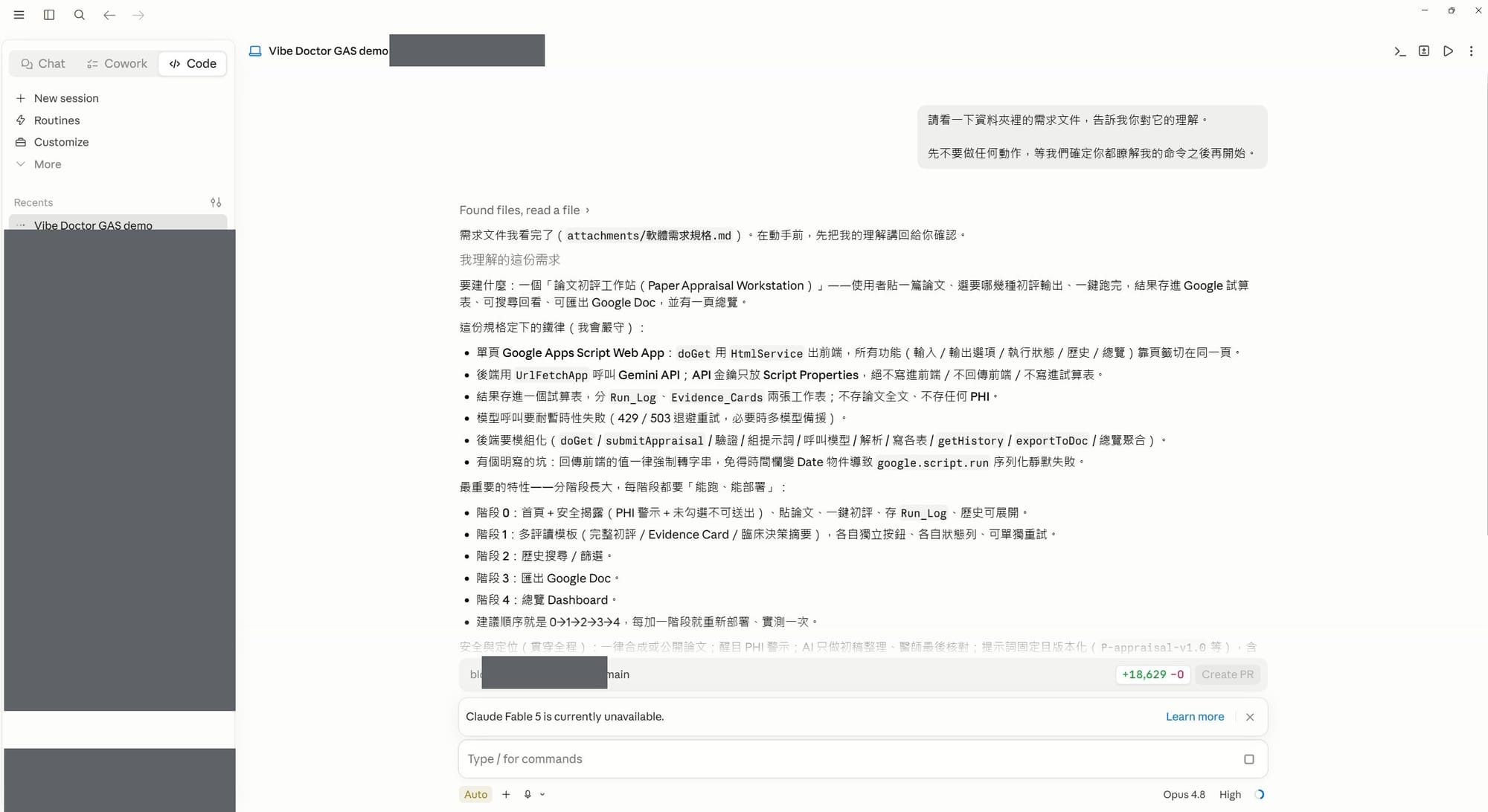
把它的回覆放大看清楚——它沒有急著動手,而是先把「要建什麼、有哪些鐵律」一條條覆述,等我點頭:

我給 Agent 的,就是上面那份需求規格(它本身也是先跟 AI 聊出來的,延續上一篇的精神),然後它就開始動手了。
這裡先說穿一個關鍵,免得你覺得像魔法:Claude Code 自己並不會去點瀏覽器。 它負責「動腦」——讀懂需求、決定下一步做什麼;真正在瀏覽器裡動手的,是它調用的 Claude in Chrome 外掛,由外掛在你登入的 Chrome 裡實際操作——開雲端硬碟、新增檔案、貼程式、按部署,都是這樣發生的。一句話:Claude Code 出腦、Claude in Chrome 出手。 接下來你看到的每一步,都是這個分工跑出來的。
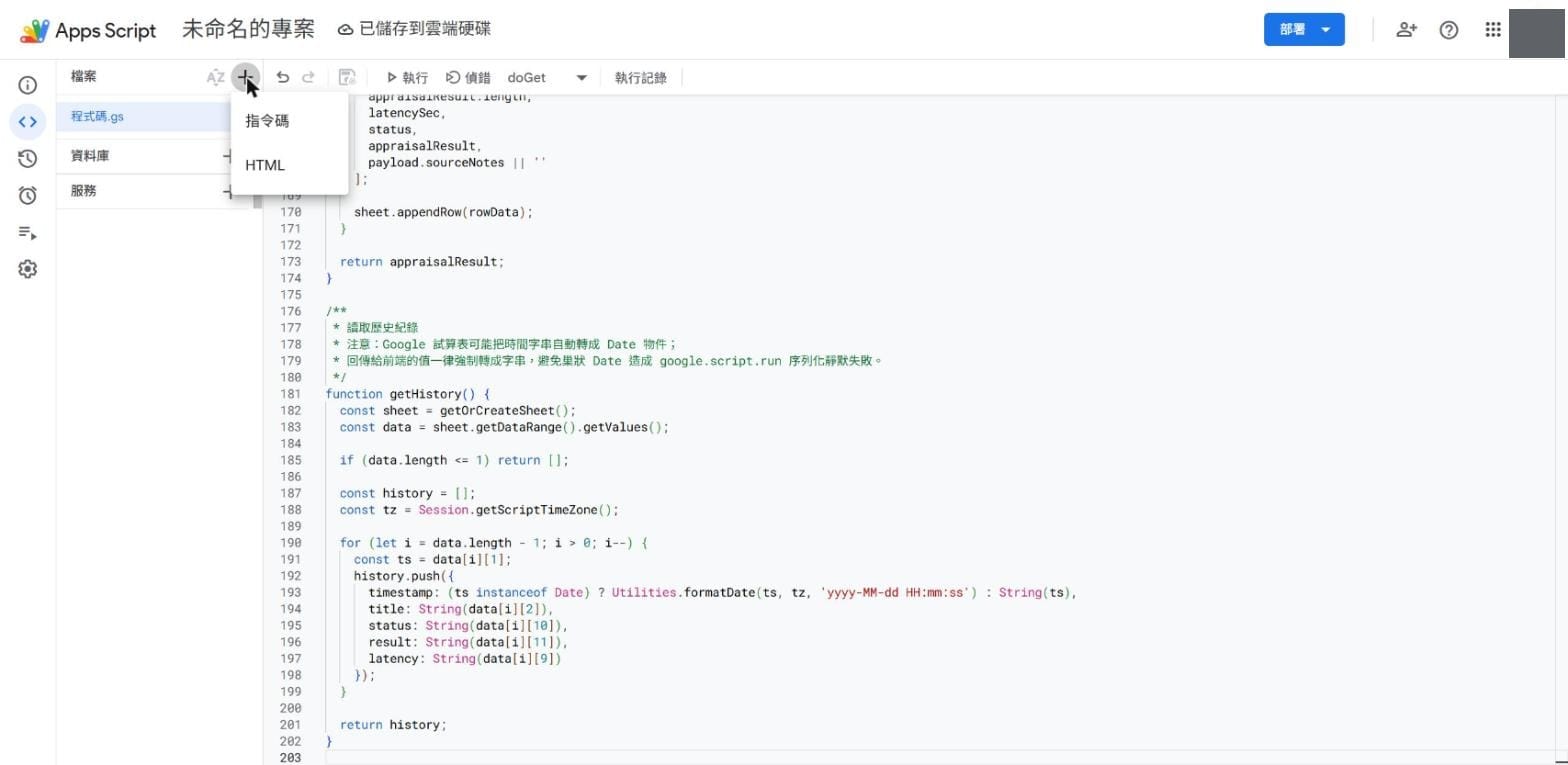
它自己進雲端硬碟、開了一個新資料夾、在裡面建了 Apps Script 專案,把自己寫的後端 Code.gs 與前端 Index.html 整段貼進編輯器——注意,這些貼上、新增 HTML 檔、命名大小寫,上一篇都是你要小心翼翼手動做的細節;這次它自己處理:
金鑰這一步,我們刻意保留給人:API 金鑰只由我親手貼進 Apps Script 的「指令碼屬性」,全程不進 Agent 的視野、也不入鏡。Agent 把屬性欄位開好,值由我填。
接著它部署成網頁。 但部署要授權存取你的 Google 帳號時,出現了第一條人機邊界:那個「Google 尚未驗證這個應用程式 → 進階 → 允許」的 OAuth 同意視窗,是一個獨立的登入視窗,Agent 的自動化抓不到它——而且老實說,這種把帳號權限交出去的敏感授權,本來就該、也只能由真人按下。所以這一下是我手點的:
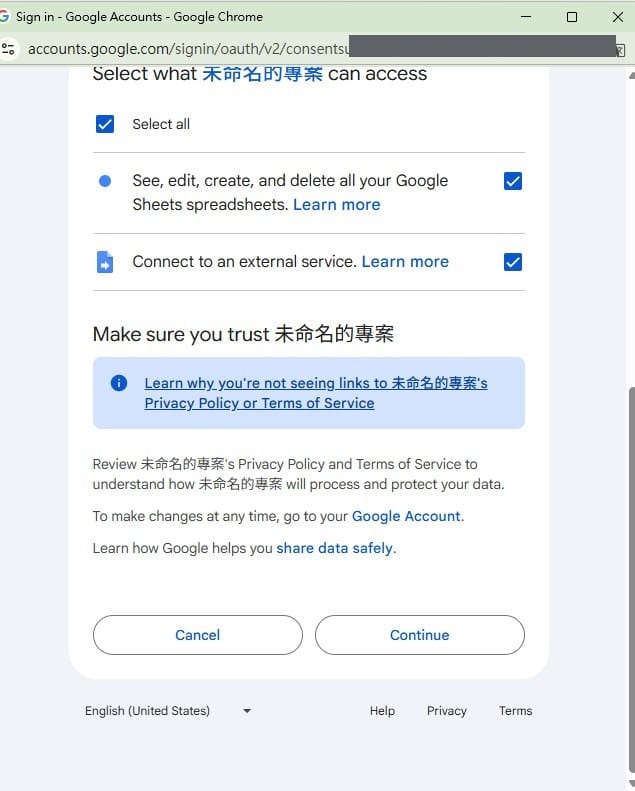
部署完成、拿到網址。它打開網頁、貼上那篇合成腎臟科論文、勾選「未輸入病人資料」、按下按鈕——幾十秒後,初評出來了:合成聲明置頂、研究類型判定、PICO、主要結果、整體評等,一應俱全;同一時間,這次執行也寫進了 Google 試算表的 Run_Log。歷史頁也正常回看。
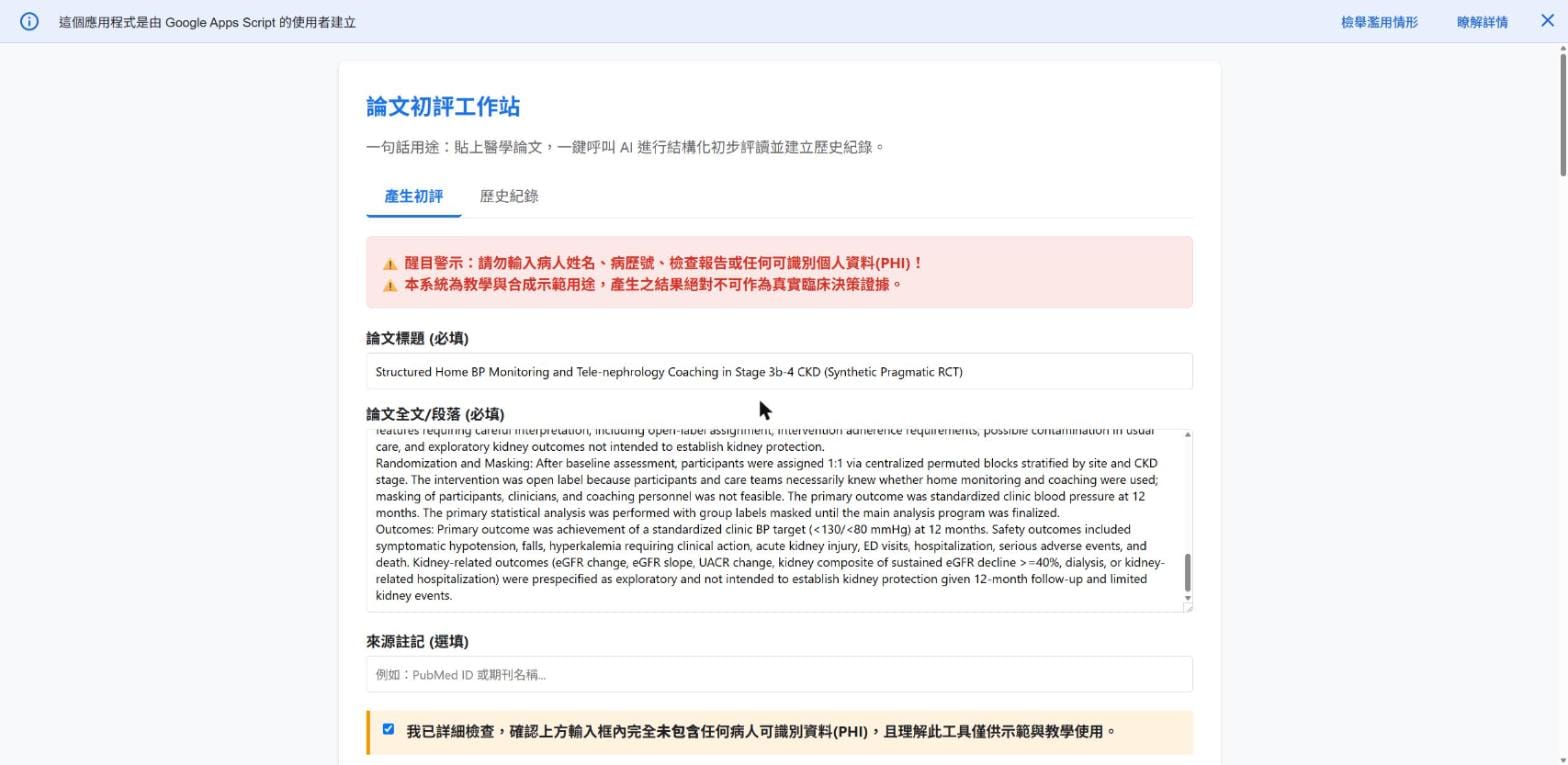
停一下,看看剛剛發生的事:一個不會寫程式的醫師,全程沒有自己貼過一行程式、沒有自己點過部署——一個 Agent 在你眼前,把一個會跑、會評讀、會存、會回看的網頁自己蓋了起來。你只出了需求、簽了一次名。
誠實補一句:基礎版這一段,Agent 跑得很順、沒撞 bug——因為它把上一篇學到的已知坑(試算表把時間轉成 Date 物件、害歷史頁卡住)一開始就避掉了。真正的考驗,在「程式開始長大」之後。
四、讓程式長大:多一種輸出,就多一分複雜
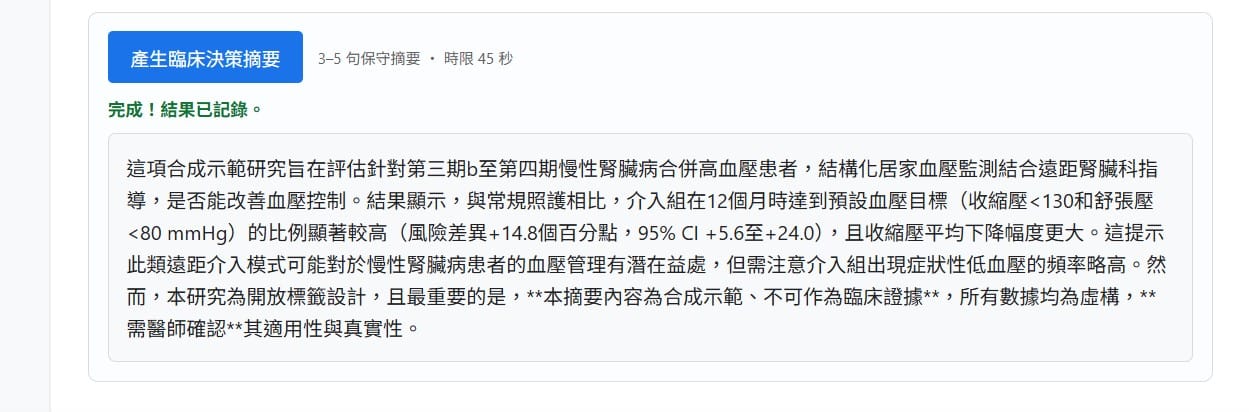
基礎版會跑之後,我請它加功能:除了「完整初評報告」,再加「Evidence Card(結構化證據卡)」和「臨床決策摘要(3–5 句保守版)」兩種輸出,各用一套固定提示詞;而且 Evidence Card 要另外存進一張結構化的 Evidence_Cards 工作表。
Agent 改了後端(多了提示詞分流、多了一張工作表)、改了前端(多了輸出選項),重新部署。程式明顯變長了。
而「變長」帶來的第一個真實後果,馬上就出現了。
五、它自己撞 bug、自己修——而且是真的撞到
按下「產生」,畫面跳出一個紅色錯誤:
API 呼叫失敗 (503):「This model is currently experiencing high demand … UNAVAILABLE」
這不是程式寫錯,而是 Gemini 模型端一時超載。但它戳中了一個只有「程式長大」才會放大的弱點:這一版一次最多要連打三個 API 呼叫(初評+卡片+摘要),呼叫一多,撞到「暫時性忙線」的機率就跟著放大;而當時只要其中一個失敗,整批就掛、什麼都沒存。
於是 Agent 動手修——而這次,動手的不是我:
- 先加「自動重試」:對 429/503 這類暫時性錯誤,退避幾秒、自動重試。改完、重新部署。
- 重試還是救不回來:再按一次,還是 503。代表 flash 不是一瞬間的尖峰,而是持續一段時間在忙,光靠同一個模型重試沒用。
- 於是再加「模型備援」:呼叫改成依序嘗試一串模型(flash → pro → 2.0-flash),主模型持續忙線就自動換下一個。改完、再重新部署。
過程中我們也順手把介面改得更聰明(這其實是你的點子):把「一顆按鈕跑三種輸出」拆成三顆獨立按鈕,各自有狀態、各自有時間上限、可以單獨重試——這樣就算某一種輸出卡住,也不會拖垮另外兩種。
最後的結果:三顆按鈕分別按下去,三種輸出全部成功跑出來,也都各自記進了試算表。Evidence Card 那一張尤其漂亮:合成聲明置頂、固定欄位(臨床問題/PICO/主要結果 55.2% vs 40.0%、OR 1.86/安全與負擔有點出症狀性低血壓/限制標了開放標籤+合成研究/使用前須確認)一格不漏,沒有亂編、也沒把腎臟探索終點吹成主要證據。
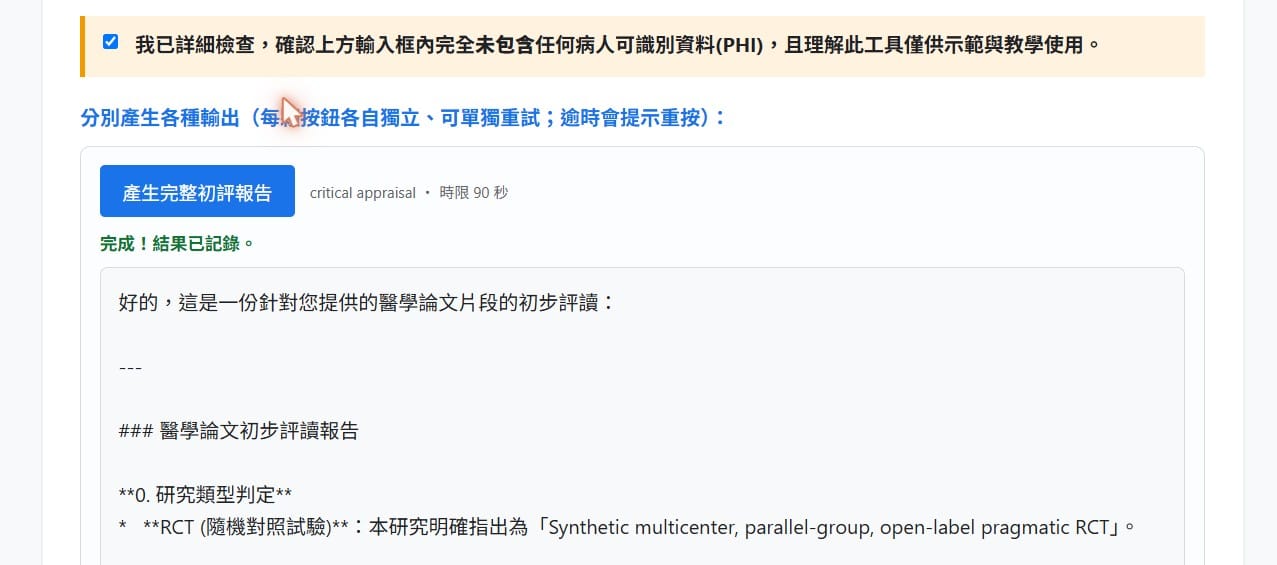
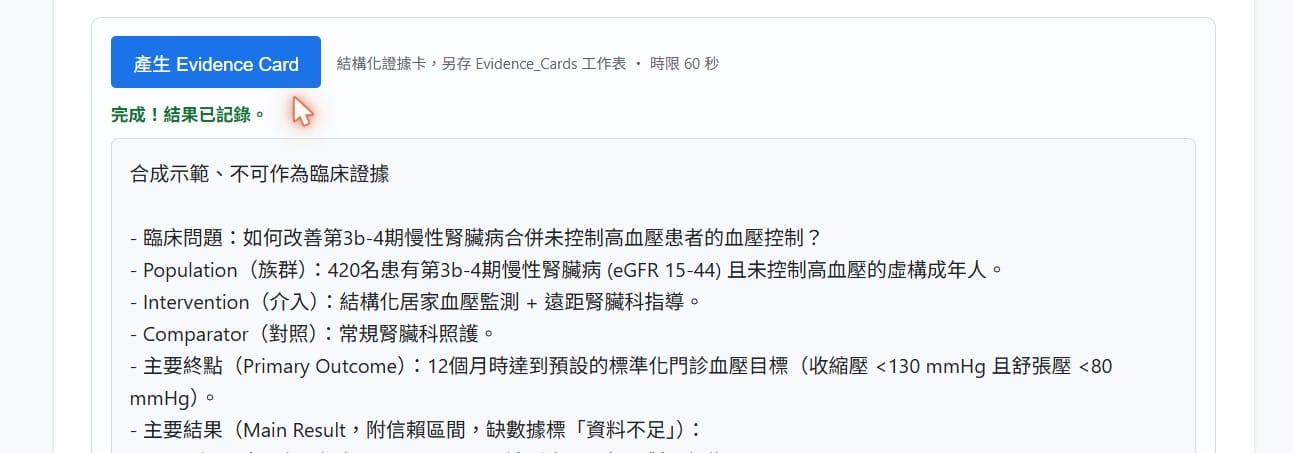
這裡要非常誠實:等我們把修好的版本拿來重測時,flash 其實已經從稍早的忙線恢復了——所以這三次成功,用的都是主模型 flash,模型備援這次並沒有真的被觸發。我們把重試與備援留著,是當「保險」;但不能宣稱「是備援救了我們」。真相是:我們撞到一段真實的模型忙線、把工具補強得更耐撞,後來模型恢復、用主模型跑成。這段「忙線—補強—恢復」的曲折,本身就是把工具養大時的日常。
順帶一提,試算表裡那兩列稍早的 錯誤: 503 紀錄,我們沒有刪掉——工具連失敗都留痕,這正是它從「按一下產生文字」變成「可追溯的工作流」的證據。
六、再長大一次:搜尋、篩選,還能變成一份 Google Doc
工具會跑、會多種輸出之後,真實用起來,你很快會想要更多——這正是看 Agent「陪程式一起長大」的好機會。我又丟了兩個需求。
「歷史紀錄要能搜尋、能篩選。」 Agent 在歷史頁加了一個搜尋框、兩個篩選下拉(依狀態、依輸出類型),打字就即時過濾。紀錄一旦累積到幾十筆,這個小功能就從「可有可無」變成「找得到東西」。
「能不能把一份初評,匯出成排版好的 Google Doc?」 Agent 在後端加了一支匯出函式、在每筆紀錄旁加了「匯出 Google Doc」鈕。按下去,它就生出一份正式文件:標題、合成揭露警語、執行 metadata(時間/模型/提示詞版本/Run ID)、整份初評全文、結尾一句「AI 初稿、需醫師審閱」。
一個誠實的小細節:建立 Google Doc 需要存取雲端硬碟的權限——但因為工具最初建立 Google 試算表時這個權限就授權過了,這次匯出並沒有再跳一次授權。我原本以為會,結果沒有;照實說。
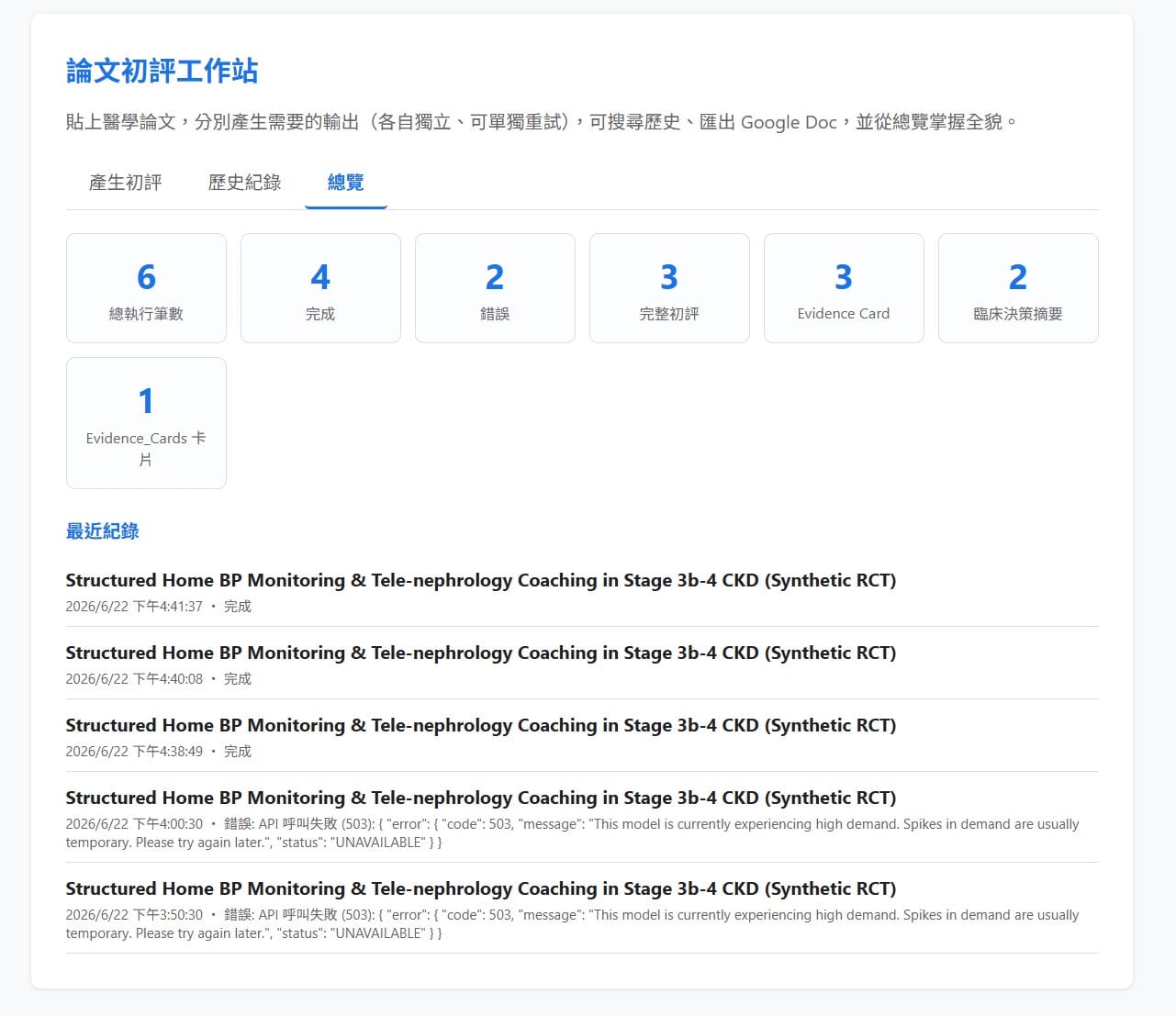
最後我又丟了一個需求:「把這些散落的紀錄,整合成一頁總覽。」 Agent 加了第三個分頁「總覽」,把 Run_Log 和 Evidence_Cards 聚合成一塊儀表板:總執行筆數、完成與錯誤數、依輸出類型(完整初評/Evidence Card/臨床決策摘要)的統計、Evidence Card 累積張數,再列出最近幾筆紀錄。一樣是它自己改前後端、重新部署、自驗——這一次不是再多一顆按鈕,而是把前面散落的資料接成一個面。
到這裡,請你退一步、用眼睛感受一下這個工具的「體積」:它已經從上一篇那一顆按鈕,長成一個有輸入、有多種輸出、能搜尋歷史、能匯出文件、還有一頁儀表板的工作站。而這一路長大,幾乎每一步都不是我動的手。

每加一個功能,模式都一樣:你出一句需求,Agent 自己改前端、改後端、重新部署、自己驗證、把紀錄留進試算表。程式一行行變長、檔案一塊塊變多,它卻沒亂——因為整份程式是怎麼長出來的,都在它管著的脈絡裡。
對照一下:同樣這一連串成長,若改用上一篇的聊天機器人——每加一個功能,你就得再複製一次它吐的程式碼、再貼一次、再部署一次、再自己測一次;改了 A 不小心弄壞 B,還得自己開 F12 抓。功能越多、改越多次,那條「跑腿稅」就滾成雪球。
七、這就是 harness engineering:它替你經營整個脈絡
回頭看這一整段,你會發現 Agent 的價值不只是「會打字」。真正關鍵的是:從頭到尾,需求、程式碼、部署狀態、執行結果,都在它管著的同一個閉環裡。
- 你說「加一種輸出」,它知道要同時改後端提示詞分流、前端選項、和試算表結構——因為這些脈絡它都記著。
- 它撞到 503,知道這是「一次連打多個 API」的後果,於是去改的是「呼叫層」而不是亂槍打鳥——因為整個程式怎麼長出來的,它都在脈絡裡。
- 改完它自己重新部署、自己再測一次——迴圈是它在跑,不是你在跑腿。
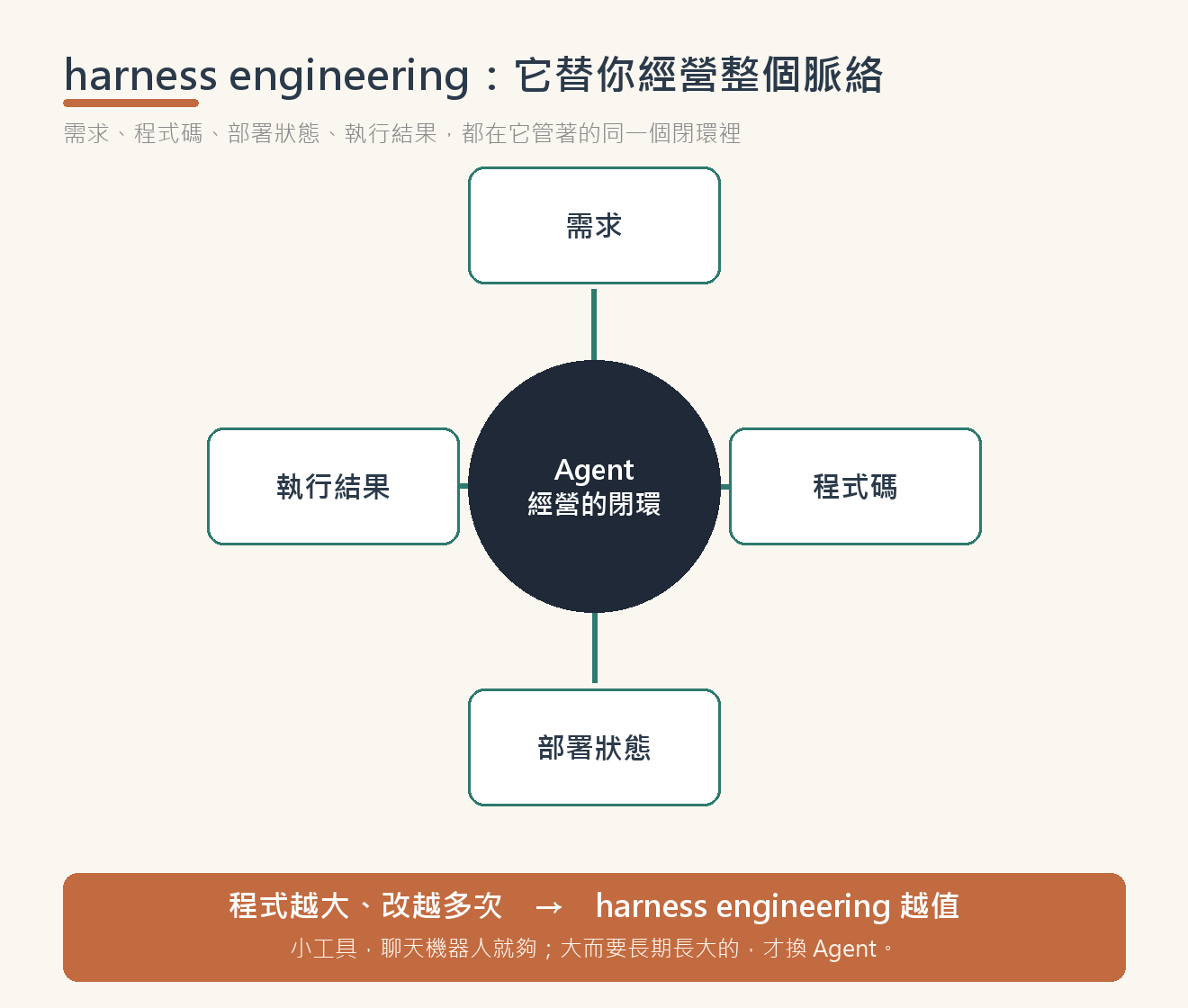
這就是為什麼程式越大、改越多次,Agent 越划算。上一篇那種小工具,聊天機器人就夠了,你跑幾趟腿也還好;但當工具開始長大、要一改再改,那個「複製貼上、開 F12、重新部署、回頭找脈絡」的跑腿稅會越疊越重——這時候,把整個迴圈交給一個替你經營脈絡的 Agent,才真正回本。
所以這不是「聊天機器人比較弱、Agent 比較強」的對決,而是看專案規模選工具:小而一次性的,聊天機器人;大而要長期長大的,Agent。
八、最後,放大一點視野:這套方法可以遷移到其他不同領域的設計
如果你看到這裡覺得「這只是寫程式的技巧」,那就太小看它了。
這套「你出需求、Agent 出手、在受管理的迴圈裡一改再改」的協作法,根本不只能拿來寫程式。同樣一套方法,可以拿去做合成論文、做長篇漫畫、做一整套教學素材、甚至生圖。為什麼?因為對一個大型語言模型來說,這些本質上是同一回事:它不在乎你要的輸出是部落格文、是論文、還是程式碼,一視同仁地用同一套「理解需求 → 產出 → 看結果 → 修」的迴圈去跑;連生圖,也只是換一個模型,背後的協作邏輯一模一樣。
講到這裡,剛好可以收一個 meta:你正在讀的這篇文章,本身也是用同一套方法做出來的。
而既然連「換一個模型」都這麼自然——你大概也猜到下一個問題了:同一篇論文、同一段提示詞,換不同的模型來跑,結果會一樣嗎?哪個比較準、比較穩、比較不會出包? 我們這次撞到的 503、加的模型備援、試算表裡那欄「用了哪個模型」,其實都是伏筆。下一篇,我們就用 Google AI Studio 把幾個模型放在一起,好好比一比。

想自己裝一個來玩?這個工具已經開源
既然講了這麼多,乾脆把這個「論文初評工作站」整包開源了——你可以下載回去,用你自己的 API 金鑰,裝一個屬於自己的版本:
🔗 https://github.com/captain-balung/vib-doctor-GAS
裡面有:完整的 Code.gs 與 Index.html、一份約 10 分鐘、不用會寫程式的安裝指南(README,含真實會遇到的疑難排解)、一份合成範例論文讓你裝好就能立刻貼上試跑,以及 MIT 授權(可自由修改、再散布)。金鑰只存在你自己的 Google 帳號裡(Apps Script 的指令碼屬性),不經過任何第三方、也不會外流。
一樣提醒:它是教學原型——請勿輸入病人可識別資料、產出不可作為臨床決策依據;AI 整理、醫師定案。
責任邊界
- 本文的網頁是教學原型,首頁清楚標示:請勿輸入病人可識別資料、結果不可作為臨床決策依據。
- 示範一律用合成(虛構)論文;真實論文也一樣,AI 的初評必經醫師人工核對。
- API 金鑰只由人親手放進伺服器端的指令碼屬性,全程不進 Agent 視野、不寫進前端、不外洩。
- 帳號授權(OAuth 同意)這類敏感動作,由真人親自按下——Agent 能出手,但這條界線留給人。
- AI 整理、醫師定案——工具與 Agent 只是把流程接起來,醫學判斷的最後一筆,仍由醫師落。