航海日誌:我和副官 Claude Code,怎麼讓一座醫學早報站每天清晨自己醒來、開口說話
第三艘船,讀者換成醫師。每天清晨自己抓論文、評重要性、寫成中文早報,再念成 Podcast、配成影片——副官 Claude Code 划槳,船長把關每一道收不回來的線:Human-First 安全閘、版權只連不貼、半夜崩在缺套件的招牌暗礁。

開發航海日誌(三)| 船長 Balung · 副官:Claude Code · 航行日期:2026-06-03 → 06-05
前兩艘船,我和副官 Claude Code 蓋過一座每天早上自己醒來的 AI 新聞站;中間還換過一次副官(Cursor),把一首 MP3 一層一層蓋成會跳舞的影片。這一篇,副官 Claude Code 回鍋,但我們要開的,是到目前為止最不能出錯的一艘船。
因為這次的讀者,是醫師。
這座站叫「每日醫學早報」——每天台灣時間清晨,它自己去全球的醫學期刊與資料庫,把過去 24 小時的腎臟、透析、CKD、心血管、代謝、老年與內科新知撈回來,自己分類、評重要性、寫成中文摘要、做「臨床—基礎轉譯」,趕在醫師喝第一口咖啡前,擺出一份當天的早報。然後——它還會把這份早報念成一集 15 分鐘的 Podcast、配成一支影片。每週日早上,再生一份週報。
AI 新聞站翻船,頂多是漏一條科技新聞。這艘船底下不一樣:畫面上每一個數字、每一句「這篇很重要」,背後都是醫師要拿來判斷的東西;而且它一腳踩在版權的雷區上——醫學期刊全文是有版權、要付費的,什麼能存、什麼只能連回去,一步都不能錯。所以這趟航行,規矩比前兩趟都更前面、更嚴。
先把兩個角色講白:船長,是我這個人類——定方向、做取捨、把關品味,還有按下所有「收不回來」的鈕。副官,就是 Claude Code——能讀懂整包專案文件、自己寫程式、跑測試、開瀏覽器驗證的 AI。下文凡寫「副官做了什麼」,就是「Claude Code 自己把那段做出來、跑出來」。
還有一件事,這篇我想做得比前幾篇更實在:前兩篇有讀者跟我說,比喻很美,但新手看完還是不知道「那我到底要動哪裡」。所以這一篇,每一章除了講故事,我都會多放一塊「如果你要自己做,具體是這樣」——明確到「打開哪個工具、打哪一句、點哪個鈕」。比喻是包裝,步驟是骨,這次兩個都給你。
這篇很長。我們從第一句話開始。


第一章:開工前的第一句話——「先讀文件,先別寫程式」
航行日期:2026-06-03
我把整個專案資料夾用 Claude Code 打開。左邊檔案樹一攤開,apps/、workers/ 都還空著,但旁邊已經躺著一整套寫好的文件——01-harness/ 資料夾裡,從 00_project_roadmap.md 一路編號到 11_development_tasks.md,十二份規格。這套東西,就是這艘船的龍骨。
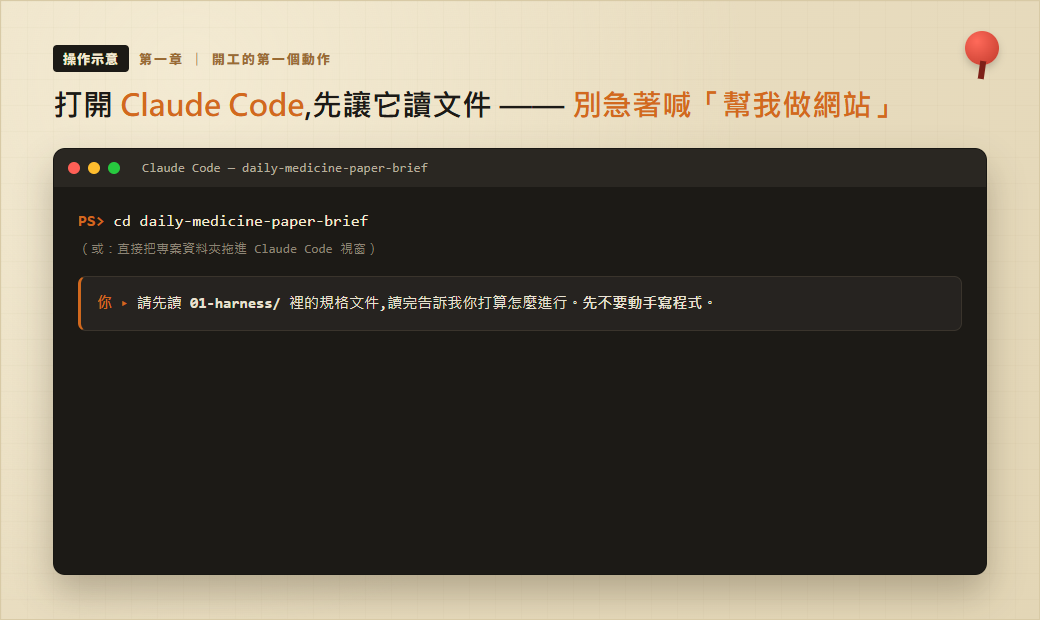
我下的第一道指令,不是「幫我做一個醫學新聞網站」。我打的是這句:
請你先讀01-harness/裡的規格文件,特別是00_project_roadmap.md、03_human_first_pipeline.md跟10_security_compliance.md。讀完告訴我你打算怎麼進行。先不要動手寫程式。

為什麼這樣下?因為「先寫文件」的回報,就在這一刻兌現:我要先確認副官讀過海圖、站回同一條航線,再讓它碰程式碼。它讀完,回我的不是程式,而是一段複述——把這艘船的鐵律一條條唸回來給我聽:
收到。我把這個專案的航向複述一遍,您確認對得上再開工:
一、MVP 優先。先做出能運作的最小版本,再逐步擴充,不要一開始就追求功能齊全。
二、Human-First。所有需要人決定的事——帳號、金鑰、開哪些資料來源、發布規則、醫學安全規則、版權規則——都要排在機器自動化之前。系統沒被人設定到「READY」,排程一律不准自動發布。
三、合法使用來源。不儲存、不散布付費全文;付費文章只標示、只連回原始出處。
四、醫學安全。每一篇都要標來源、證據等級、限制與 preprint 狀態;preprint 一定要明寫「未經同儕審查」。
五、架構分工清楚:Vercel 管網站、Supabase 管資料、Render 管那些跑很久的 Python 工作。
六、API 金鑰絕不寫死在程式裡、絕不進 git。
它複述的航向,跟我海圖上畫的對得起來。對得上,才開工。這就是我心目中 Vibe Coding 的第一步——不是對著 AI 喊一句就生出網站,而是先讓它跟你站在同一張海圖前,把你信什麼、怕什麼,先講清楚。對一個要給醫師看的站,這一步尤其省不得。
如果你要自己做,具體是這樣:
- 打開 Claude Code,用
cd進到你的專案資料夾(或直接把資料夾拖進 Claude Code 視窗)。 - 先別喊「幫我做網站」。第一句話打:
請先讀 01-harness/ 裡的規格文件,讀完告訴我你打算怎麼進行,先不要寫程式。 - 等它把你的鐵律「複述」回來、你逐條確認對得上,再回一句:
對得上,開工。
誰掌舵、誰划槳:白紙黑字的三條界線
分工不能只靠精神喊話。它白紙黑字寫在規格裡,把界線切成三種——這也是這整篇日誌的骨架:
- 副官自己做、不必問我:讀寫程式碼、跑測試、在本機起伺服器預覽、打包、開瀏覽器自己截圖比對、本機 commit。這些可逆、可自動,丟回來問我反而是浪費。
- 副官一定要停下來、當場點名請我做:安裝新套件、把程式 push 上雲端、部署上線、用我的真實金鑰去呼叫付費 AI。這些要嘛花錢、要嘛對外、要嘛收不回來。
- 只有我能親手做的(副官根本沒權限碰):到 GitHub 開 repo、到 Vercel/Supabase/Render 的 Dashboard 設環境變數、把真實 API 金鑰貼進去、在「初始設定面板」上把這座站從
SETUP_REQUIRED一路設定到READY,以及最後——親手按下發布。
所以接下來你會一直看到一個畫面:副官划得飛快,但每撞到一條「對外、花錢、收不回來」的界線,它就停下來,具體地點名請我出手。一隻腳踩在岸上、一隻腳踩在船上——Vibe Coding 的分工,就是這個樣子。
這艘船特有的紅線:機器自動化之前,人要先把安全邊界設好
這趟和前兩趟最不一樣的地方,寫在 03_human_first_pipeline.md 的第一句:所有需要人決定的事,都必須發生在機器自動化之前。
講白話:這座站不是寫完程式就讓它自己每天亂跑。它有一個「初始設定面板」,人要先在上面把九件事設好——帳號與角色、金鑰、開哪些資料來源、各主題的權重、發布規則、醫學安全規則(preprint 警語、證據等級、免責聲明)、版權規則,最後跑一次「測試管線」全部通過。系統的狀態要從 SETUP_REQUIRED 一路走到 READY,排程才被允許自動發布。沒到 READY,它一篇都不准發。
船長,我把「人先設、機器後跑」這條釘進程式了:首頁如果偵測到系統還沒 READY,管理員一進來看到的不是公開首頁,而是初始設定面板。金鑰我只檢查「有沒有設、連不連得上」,絕不把金鑰本身顯示在畫面上。要等您把該設的都設好、測試管線跑綠,我才讓排程接管。
我特別欣賞這個設計:它把「醫學內容不能亂發」這件事,變成程式層面的一道閘門,而不是靠人記得小心。對一個會自己每天發稿的系統來說,這種「沒準備好就發不出去」的硬性煞車,比任何叮嚀都可靠。
第一章先到這。船還沒下水,但航向、分工、紅線都對齊了。下一章,我們讓這艘船先空著下水——只是這次,船底要同時點燃三具引擎。

第二章:先讓空船下水——只是這次,船底有三具引擎
航行日期:2026-06-03
第一章講完規矩,副官沒有急著去寫抓論文、叫 AI 那些「酷」的東西。它照著「MVP 優先、部署先行」的鐵律,先做一件看起來什麼都沒做的事:讓一個空殼先成功上線。它用 create-next-app 搭好骨架,把首頁改成一張極簡測試頁,在本機跑起來、自己開瀏覽器確認畫面正常,然後就走到那道它跨不過去的界線,點名請我去 GitHub 開 repo、把網址貼回來。這一段,跟前兩艘船一模一樣——先讓水管通水,再裝水龍頭。
真正不一樣的,是這艘船的船底。前兩艘要嘛只有一具引擎(靜態網站),要嘛根本沒有後端(瀏覽器內跑)。這一艘,副官在複述航向時就先跟我把架構講白了——它底下要同時點燃三具引擎:
船長,這座站的活,我建議拆給三朵雲,各司其職:
Vercel 管網站——把每天的早報、文章頁、Podcast 播放器、初始設定面板渲染出來給人看。
Supabase 管資料——文章 metadata、摘要、分數、早報、Podcast、檔案儲存,全部存這。
Render 管粗重的活——每天清晨那條「抓取→去重→叫 AI→寫早報→生 Podcast→做影片」的長鏈,跑在 Render 的 Python worker 上。

我追問了一句:「網站不是已經有 Vercel 了嗎?為什麼還要多接一個 Render?」副官的回答,是這艘船最關鍵的一個技術選型:
因為 Vercel 那種「網頁伺服器」適合幾秒內回應的輕活,它有執行時間上限,關不住跑很久的工作。但我們這條鏈,光是叫 AI 分析十幾篇論文、再把早報念成十幾分鐘的 Podcast、最後配成一支影片,動輒好幾分鐘——這是會把 serverless 撐爆的長工。所以規格裡白紙黑字寫:「不要在 Vercel 的路由裡跑長工。」這種長活,要交給 Render 這種能安穩跑幾分鐘、不會被中途掐斷的背景 worker。
這就是「對的活,放對的引擎」。網站要快,所以放 Vercel;每天清晨那條會花好幾分鐘的長鏈,要穩,所以放 Render;中間的資料與檔案,交給 Supabase。三朵雲,各做自己最擅長的事。
如果你要自己做,具體是這樣(讓空殼先上線):
- 到
github.com/new開一個 repo,三個初始化選項(README / .gitignore / license)都不要勾(本機已經準備好了,勾了會打架)。把 URL 貼回 Claude Code,它幫你git push。 - 到 Vercel → Add New → Project,import 這個 repo,按 Deploy。先別管功能,讓空殼上線就好。
- 到 Vercel 的 Settings → Environment Variables,只放公開安全的兩個:
NEXT_PUBLIC_SUPABASE_URL、NEXT_PUBLIC_SUPABASE_ANON_KEY。後端金鑰(service role、AI key)千萬別放進 Vercel,那些是 Render 專用的。
幾十秒後,Vercel 的網址活了過來。空船下水了。三具引擎還沒全部點火,但船塢、儀表板、油路都接上了。下一章,我們把第一具、也是最重的那具引擎——每天清晨自己抓論文的那條鏈——裝進船艙。

第三章:把引擎裝進船艙——抓取、去重,然後才敢叫醒 AI
航行日期:2026-06-03
空船能自動上線之後,才開始裝真正的引擎。這座引擎的工序是一條鏈:並行抓取 → 正規化 → 去重 → 標記取用狀態 → 叫 AI 分類評分摘要 → 寫進資料庫。
抓取這段副官完全自理:它寫好一層共用的抓取器,接上一整排醫學來源——PubMed(腎臟、心血管、代謝、老年、AI 醫療各一組關鍵字查詢)、Crossref(補 DOI、出版社、授權資訊)、Europe PMC(補 PMCID 與合法全文連結)、Unpaywall(查這篇是不是 Open Access)、各大期刊的 RSS(NEJM、Lancet、JAMA、Kidney International、JASN…),還有 bioRxiv / medRxiv 兩個 preprint 站。寫完它自己跑了一個測試腳本,確認每個來源都撈得到東西,才回報。這一段我沒插手——可逆、可自動、出錯也只是本機跑不動。
但鏈條中間那一步,副官特地停下來跟我敲定順序——這也是這艘船省錢與守規矩的關鍵:
船長,這裡有個順序我想跟您確認:去重一定要排在叫 AI 之前。
同一篇論文,PubMed、Crossref、期刊 RSS 可能各抓到一次,明天的時間窗也還會再抓到它。如果不先擋掉就送進 AI,等於替同一篇論文重複付一次 AI 的錢。
我的去重是一層一層比對:先比 DOI、再比 PMID、再比 PMCID,最後才用「正規化標題 + 第一作者 + 年份」做模糊比對。重複的合併成一篇、保留所有來源連結,真的新的才送進 AI。

我拍板。對一個每天都會自己花錢叫 AI 的系統,省錢的紀律不是上線後才補,是設計第一天就釘進鏈條裡。
叫 AI 之前,先決定「這篇能不能碰」
去重之後、叫 AI 之前,還插了一道別的站沒有的關卡:標記取用狀態(access status)。每篇文章會被貼上一個標籤——OPEN_ACCESS(開放取用)、PMC_AVAILABLE(PMC 有全文)、PREPRINT_AVAILABLE(預印本)、INSTITUTIONAL_ACCESS_NEEDED(要機構登入)、ABSTRACT_ONLY(只有摘要)。
這個標籤決定了 AI 能讀到哪裡:合法開放的全文,AI 可以讀;付費牆後的全文,AI 只准讀公開的標題與摘要,絕不去碰、也絕不儲存付費全文。這條線,第七章會變成整篇最深的一道暗礁。
船長,提醒一個小坑:有些文章查不到取用狀態,我先給它 UNKNOWN。但畫面上直接寫「UNKNOWN」太冷,讀者會以為壞掉。我把它顯示成 Full text unknown(全文狀態未知),意思一樣,但人看得懂。停下來請我建資料庫
引擎要有地方存東西。副官從規格生出完整的建表 SQL,存成 supabase/migrations/ 底下一支支 migration 檔——這一步它自己做。但真正去資料庫建表,又是一道它沒權限的界線,它停下來點名請我:到 Supabase Dashboard → SQL Editor,把 migration 貼上去、按 Run,確認文章表、早報表、Podcast 表、管線記錄表都建好。我貼、我跑、我確認、回報。副官接手,把讀寫資料庫與那條去重邏輯寫成程式。
引擎的另一半是 AI。副官接上 Anthropic 的模型,讓它對每篇真的新的論文做一整套分析:分到哪一科、是什麼研究類型(RCT?統合分析?還是動物實驗?)、證據等級幾分、五個面向的重要性評分(臨床衝擊、證據強度、新穎性、專科相關、教學研究價值),加總 22 分以上才掛上「今日必讀」。再寫出中文摘要、臨床意義、基礎機轉,還有這站的招牌——臨床—基礎轉譯。

而且,規格裡釘死一條醫學紅線:preprint(預印本)一定要標明「尚未經同儕審查」、不可給最高證據分;只有摘要的,要標明「尚未進行完整全文分析」。AI 寫得再漂亮,這些警語一個都不能少。引擎的心臟裝好了,而且從第一下心跳就帶著醫學的安全鎖。


第四章:每天清晨的鬧鐘,與那道「沒準備好就發不出去」的閘門
航行日期:2026-06-03
引擎能轉,還得有人每天清晨去點火。這就是排程(cron)。我們把它設在台灣時間每天清晨 06:30,趕在醫師起床查房前把早報擺上桌。但點火時間藏著一道老暗礁,副官先挑明:
船長,Render 的排程吃的是 UTC。台灣清晨 06:30,換算成 UTC 是前一天的 22:30。所以render.yaml裡我寫的是30 22 * * *,不是30 06。同一條鐵律也貫穿資料庫:所有時間一律存 UTC,只在畫面上才換算成台灣時間,免得某天半夜跨日時,把論文歸錯日期。

但這艘船的排程,比前一艘多了一道更重要的閘門。還記得第一章那條 Human-First 紅線嗎?它在這裡變成一道硬性煞車:系統狀態沒走到 READY,排程一篇都不准自動發布。
所以 Render 上那支每天被叫醒的程式,開跑前會先做兩件事:一是檢查必要的金鑰與環境變數在不在(`SUPABASE_SECRET_KEY`、`ANTHROPIC_API_KEY`、`OPENAI_API_KEY`…),二是確認系統是 READY。少一樣,它寧可不跑,也不要發出一份殘缺的早報。(這個「開跑前先自我檢查」的設計,埋了一個伏筆——第六章你會看到,它差一點就救了我們,卻又差一步沒救到。)
如果你要自己做,具體是這樣(把排程掛上 Render):
- 到 Render Dashboard → New + → Blueprint,連上你的 GitHub repo(它會讀 repo 裡的
render.yaml)。 - Render 會問你要幾個密鑰,這一步只有你能做:把
SUPABASE_SECRET_KEY、ANTHROPIC_API_KEY、OPENAI_API_KEY一個個貼進去。金鑰要經過你的手,不從 AI 那邊流過去。 - 建好之後,先別等明天早上——打開那個 cron 服務,按一次 Trigger Run 手動測一遍。看 Supabase 有沒有長出今天的早報,就知道整條鏈通不通。
我把金鑰一個個貼進 Render,手動觸發一次。幾分鐘後,Supabase 裡長出了當天的早報、Podcast 腳本、音檔。然後我們做了一件很安靜的事——什麼都不做,去睡覺。隔天早上,我還沒碰電腦,網站上已經擺著當天的醫學早報。沒有人點火,是那道排程在天還沒亮時自己醒來,把整條鏈跑完了。

第五章:不只給眼睛看,還要給耳朵聽——和那段被人耳一遍遍校過的聲音
航行日期:2026-06-03 → 06-04
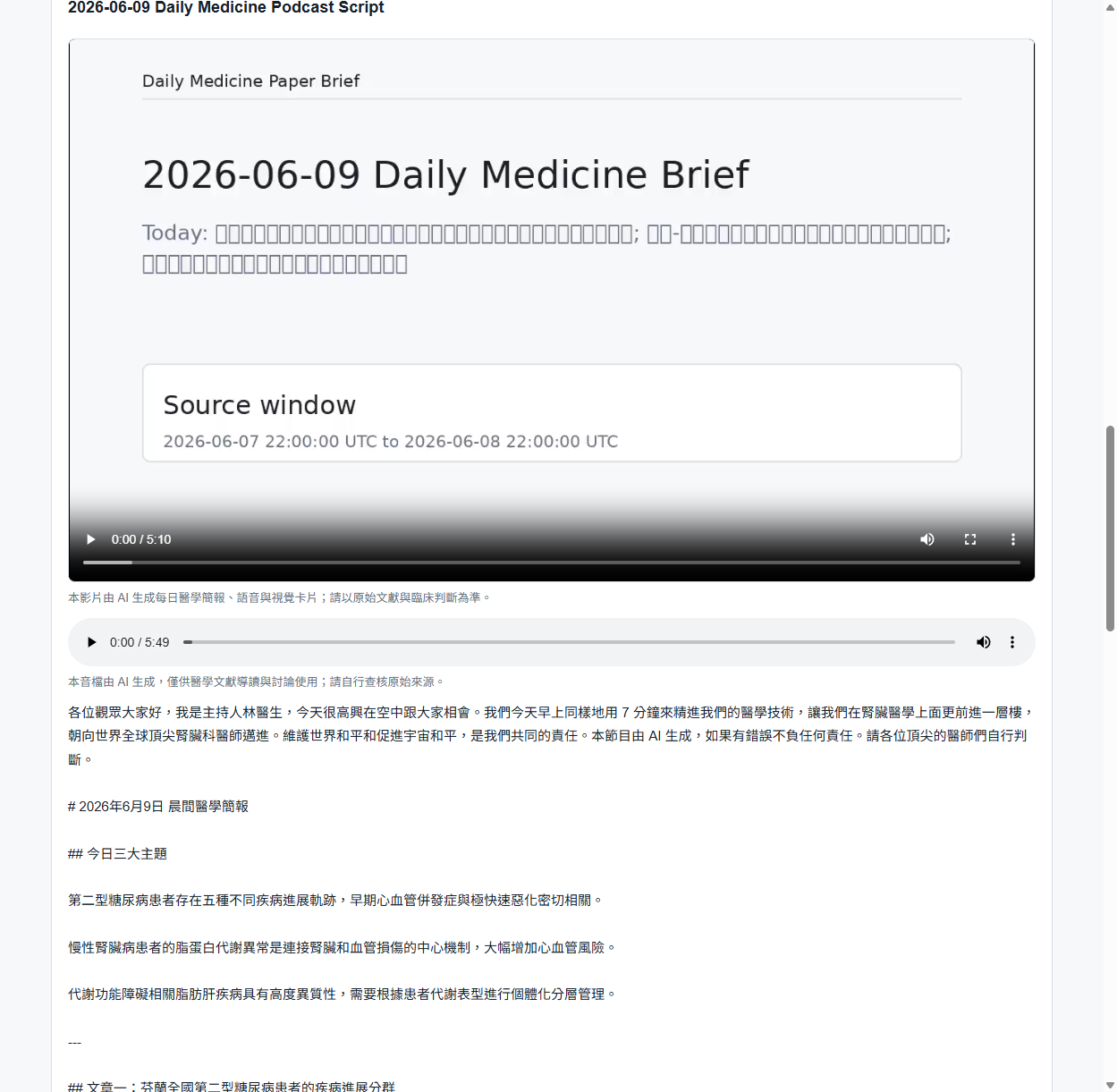
早報能讀了,但這艘船的野心不只如此:它要讓醫師通勤路上用聽的。所以引擎的最後一段,是把當天的早報念成一集 Podcast。
副官先把純文字的鏈打通:AI 寫出 Podcast 腳本 → 因為 OpenAI TTS 有輸入長度上限,先把長腳本切段 → 逐段轉成語音 → 接成一支 MP3 → 上傳 Supabase Storage → 在早報頁掛上播放器。第一次在線上聽到它把當天的腎臟新知念出來,那種感覺很奇妙——文字,第一次有了聲音。
但「能出聲」離「好聽」還很遠。接下來幾天,真正花力氣的,是一段很瑣碎、卻最能說明「人定方向」的活:用我的耳朵,一遍遍替 AI 的聲音校音。
船長:節目要有個記得住的開場。給它一個主持人身份——就叫「林醫生」,開場用一段刻意誇張、快節奏的話術破冰,再切回正常、專業的播報聲。開場跟正文,用不同的語氣指令。
然後是一連串只有耳朵能拍板的微調,我把它原原本本記在日誌裡:開場第一版設 1.85 倍速,太快、聽不清,降到 1.5 倍;正文 0.95 倍速,太拖,加到 1.05 倍;預設的 alloy 嗓音太硬,換成更溫的 marin,並給它「溫暖、穩定、台灣醫師播客」的語氣指令。連一個小坑都記下來:腳本裡的 Markdown 標題(像「開場」「結尾」)要先拿掉,不然 TTS 會把「開場」兩個字也念出來。還有,原本目標 15–20 分鐘的節目,醫師回饋說每天聽太長,於是砍成約 7 分鐘、只深談前三篇,而且不念期刊名、PMID、DOI 這些唸出來很出戲的東西。
後來甚至再加一層:把聲音配成一支影片(MP4),一樣存進 Supabase。於是同一份早報,有得讀、有得聽、有得看。
這一整章沒有什麼高深的技術,卻是我最喜歡的一段。因為它把「人定方向、AI 划槳」講得最清楚:機器能飛快地把聲音生出來,但「快了 0.1 倍」「這個嗓音太硬」「這裡太長」——這些,只有坐在那裡一遍遍聽的人,才能拍板。

第六章:那個早上,日報沒有醒過來
航行日期:2026-06-05
每一趟航行都有一道最深的暗礁。這一趟的,在一個再普通不過的早上撞上。
2026-06-05 早上,我習慣性打開網站,想看當天的早報——沒有。該醒來的那份早報,沒醒。
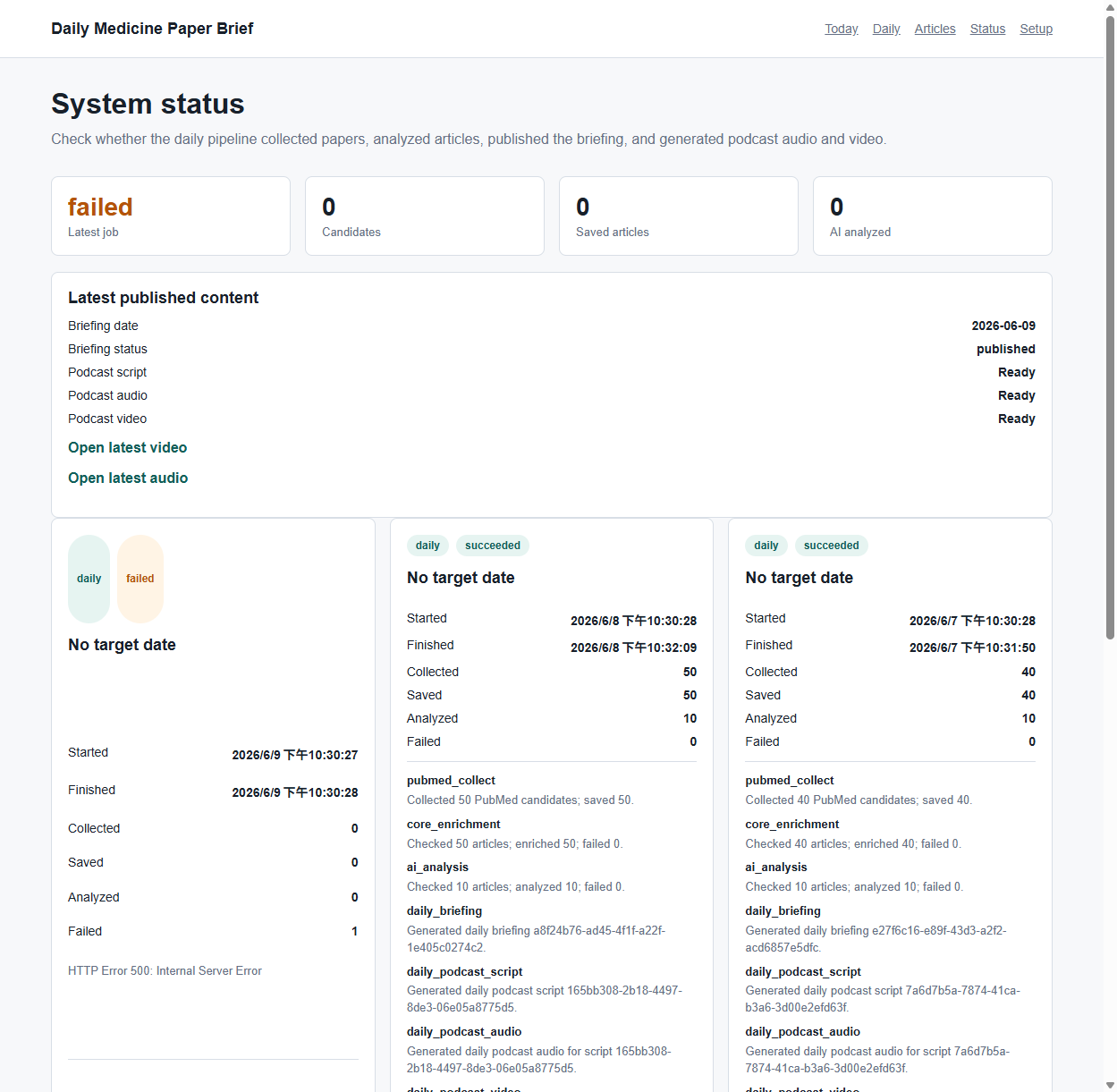
我把這件事丟給副官,我們一起開始查案。第一現場是 Supabase:
船長,Supabase 這邊查到了:今天沒有任何一個成功的排程工作。連失敗紀錄都很乾淨——這通常代表,程式根本還沒跑到「會寫資料庫」那一步,就先掛了。問題不在醫學鏈本身,在更前面。
要看「更前面」發生什麼事,得去 Render 的日誌。這裡副官做了一個關鍵的操作改進——它請我裝上官方的 Render CLI,從此能直接在終端機撈服務清單、部署紀錄、跑時日誌。裝好、撈出 06:30 那班的 log,病根當場現形:
找到了,而且很乾脆。Render 的排程有準時觸發(UTC 2026-06-04T22:30),但它在程式剛開始 import 的時候就崩了:ModuleNotFoundError: No module named 'PIL'。
根因不是醫學管線,是部署設定漂移:我們後來為了做影片,在 repo 加了workers/requirements.txt,裡面有pillow、imageio-ffmpeg。但 Render 上這個服務的 build command 還停在舊的true(什麼都不裝),所以那兩個影片用的套件從來沒被安裝過。程式一 import 影片模組,就在第一行炸掉。

這道暗礁特別有教育意義:它不是醫學邏輯錯,而是「程式碼長出了新需求,但部署環境沒跟上」。更諷刺的是——還記得第四章那個「開跑前先檢查環境變數」的自我檢查嗎?它檢查了金鑰,卻沒檢查「該裝的 Python 套件裝了沒」。它差一點就攔下這次崩潰,卻差了這一步。
救援分兩手:先止血,再治本。
止血——我在本機手動把當天的管線補跑一遍。這裡又撞到一個 Windows 的小礁:某篇 PubMed 標題裡有個特殊字元,讓 Windows 終端機編碼炸掉,靠設定 PYTHONIOENCODING=utf-8 繞過。補跑成功,2026-06-05 的早報、腳本、MP3、MP4 全部生出來,線上補上了。
治本——把 Render 那個漂掉的設定改回來:build command 從 true 改成 pip install -r workers/requirements.txt,重新部署。部署日誌這次乾乾淨淨地印出 pillow==12.2.0、imageio-ffmpeg==0.6.0 安裝成功。順手把 Render 環境也補齊:TTS_VOICE=marin、PYTHONIOENCODING=utf-8。
如果你要自己做,具體是這樣(用 Render CLI 查為什麼半夜的排程掛了):
- 裝官方 CLI,登入:在終端機跑
render login(會開瀏覽器授權)。 - 找出你的服務:
render services,認出那個 daily pipeline 的服務 ID。 - 撈跑時日誌:
render logs <service-id>,往上找紅字。最常見的不是邏輯錯,而是ModuleNotFoundError這類「環境沒裝對東西」。
這道暗礁留給我一句話,我記在日誌結尾:看不見的依賴,會在沒人看著的半夜,讓整條鏈崩在第一步。它也標進了海圖——下一個該補的安全網,是讓程式「開跑前先試著 import 一遍該用的套件」,把這種崩潰擋在排程之前。

第七章:寧可少貼,也不違法重製一個字
航行日期:2026-06-03
如果說第六章是「半夜會崩的暗礁」,這一章就是「一開始不閃開、遲早會撞上的法律暗礁」——而且它是醫學/學術站才有的。
醫學期刊的全文,絕大多數是有版權、要付費的。一個天天自動抓論文、自動生內容的站,最容易、也最危險的一條路,就是順手把出版社的全文、摘要、圖表整碗端過來重貼。那會很「豐富」,但那是違法重製。所以這條線,我們在設計第一天就劃死,寫進安全規格:
船長,版權這塊我用一條原則處理:這座站賣的是「AI 的整理、評論與引導」,不是「別人的原文」。
可以存、可以用的:標題、作者、期刊、日期、DOI、PMID、摘要、開放取用的合法全文,還有我們自己 AI 生成的摘要與評論。
不准碰的:付費的文章本體、出版社 PDF、期刊圖表。付費牆後的文章,只標示、只連回原始出處,引導讀者透過醫院或圖書館的機構登入去看正版。

這條原則,具體落到產品上是一個很有感的動作:文章詳情頁原本會顯示原文摘要全文,後來我們把它整段拿掉,改成一段「來源查證指引」——把 DOI、PMID、出版社連結、授權條款擺出來,讓讀者自己回到正版去讀。同時整站掛上「來源與使用聲明」,把出處與署名一直擺在看得見的地方。
表面上,這是「主動讓內容變少」。但對一個要給醫師長期信任的站來說,這正是價值所在:它整理、它評論、它幫你導航回正版,但它不偷一個字。乾淨,比豐富更重要——這和第一章那條 Human-First 的紅線,其實是同一種潔癖。

尾聲:人定方向,AI 划槳——而那顆發布鈕,只有醫師能按
三趟航行下來,我越來越確定一件事:真正掌舵的,從來不是某個 AI 工具,而是那條清清楚楚的交班線——哪些副官自己做、哪些它停下來點名請我、哪些只有我能親手碰。
這一艘船,把這條線畫得比前兩艘都更前面。因為讀者是醫師,所以「人先把安全邊界設好,機器才准自動跑」(Human-First);因為踩在版權雷區,所以「寧可少貼,也不違法重製」;因為內容會被拿去判斷,所以每一篇都帶著證據等級、preprint 警語、來源連結。AI 把船開得又快又穩,可以在我睡覺時自己抓論文、寫早報、配 Podcast——但每一道「對外、收不回來」的界線前,它都停下來,把鈕留給我。
說個你可能已經猜到的事:你現在讀的這篇航海日誌,是副官 Claude Code 寫的初稿。我請它回頭翻整個專案的文件、git 歷史、那些踩過的雷,把我們這一路怎麼交班,重新講成一個故事。它做完了,然後停在那道從第一章就立好、它永遠跨不過去的界線上:
船長,稿子我寫好了。但最後這一步我做不了,也不該做:按下發布。這篇要對外、收不回來,而且是您的名字、您的部落格,寫的還是要給醫師看的東西。發文這顆鈕,從頭到尾,只有您能按。
於是這篇文章自己,就成了整艘船分工的最後一個註腳。現在,台灣時間每天清晨,這艘船會自己把當天的醫學新知,讀成早報、念成 Podcast、配成影片,擺上桌。沒有人點火。
人定方向,AI 划槳。而在醫學這片海上,那顆發布鈕,我握得比哪一次都緊。
📦 想對照原件的:這趟航行的完整程式碼,連同那套讓副官站回航線的 harness 規格文件(從 00_project_roadmap.md 到 11_development_tasks.md),都放在 GitHub repo 裡 👉 github.com/captain-balung/daily-medicine-paper-brief



